Rerank_EmbeddingModel
Rerank
Việc rerank sau khi đã lấy kết quả tìm kiếm (như trong trường hợp bạn đã tìm được 5 kết quả tốt nhất dựa trên cosine similarity) có thể là cần thiết hoặc không cần thiết, tùy thuộc vào mục tiêu và yêu cầu cụ thể của bài toán bạn đang giải quyết.
Ý nghĩa của reranking:
-
Tối ưu lại thứ tự kết quả: Mặc dù bạn đã lấy ra các kết quả gần nhất dựa trên cosine similarity (những điểm số cao nhất), nhưng rerank có thể giúp cải thiện thứ tự kết quả bằng cách sử dụng một số thông tin bổ sung hoặc một mô hình khác để đánh giá lại các kết quả tìm được. Ví dụ, bạn có thể sử dụng một mô hình học sâu (fine-tuned) để đánh giá lại thứ tự của các kết quả, kết hợp thêm các yếu tố như relevance hay importance của các kết quả.
-
Đánh giá bổ sung với các tiêu chí khác: Nếu chỉ dựa vào cosine similarity (hoặc độ tương đồng vector), bạn có thể bỏ qua những yếu tố khác như:
- Độ dài văn bản: Một số văn bản có thể rất ngắn và không chứa đầy đủ thông tin, trong khi một văn bản dài có thể chứa nhiều thông tin hữu ích hơn.
- Định dạng câu hỏi: Một số mô hình có thể biết cách điều chỉnh câu trả lời dựa trên cách câu hỏi được đặt ra (ví dụ: có thể đánh giá lại câu trả lời có liên quan đến dạng câu hỏi hơn).
-
Các mô hình học máy để rerank: Thông thường, sau khi tìm được các kết quả từ search engine (như Qdrant), bạn có thể rerank các kết quả này bằng cách sử dụng các mô hình đã được fine-tuned cho việc đánh giá relevance giữa truy vấn và kết quả, như:
- BERT hoặc RoBERTa fine-tuned trên bài toán Ranking.
- Learning to Rank: Phương pháp này sử dụng các mô hình học máy (như XGBoost, LightGBM) để học cách xếp hạng các kết quả dựa trên các đặc trưng của truy vấn và tài liệu.
Khi nào không cần rerank:
Nếu bạn đã lấy ra 5 kết quả tốt nhất dựa trên cosine similarity từ Qdrant (một hệ thống vector search), thì về lý thuyết, các kết quả này đã có độ liên quan khá cao với truy vấn của bạn. Trong trường hợp này, bạn không nhất thiết phải rerank nếu các kết quả này đáp ứng đủ yêu cầu về độ chính xác và không cần thêm sự điều chỉnh nào. Các trường hợp này có thể bao gồm:
- Query đơn giản: Truy vấn không quá phức tạp và không cần phải điều chỉnh thứ tự kết quả.
- Sự khác biệt nhỏ: Các kết quả đã có điểm cosine similarity gần nhau, và thứ tự ban đầu đã đủ tốt.
Khi nào rerank là cần thiết:
- Cải thiện chất lượng kết quả: Khi bạn cần cải thiện độ chính xác của kết quả tìm kiếm, reranking có thể giúp điều chỉnh lại các kết quả và đưa ra thứ tự tối ưu hơn.
- Truy vấn phức tạp: Nếu truy vấn có sự phức tạp hoặc có sự mơ hồ, reranking có thể giúp mô hình hiểu được nội dung ngữ nghĩa của truy vấn một cách chính xác hơn.
- Cải thiện trải nghiệm người dùng: Nếu bạn muốn kết quả không chỉ giống nhau về nội dung mà còn phù hợp với mục đích cụ thể của người dùng, reranking có thể giúp tạo ra các câu trả lời tinh tế hơn, tốt hơn cho yêu cầu của người tìm kiếm.
Ví dụ thực tế:
Giả sử bạn đang xây dựng một hệ thống trả lời câu hỏi tự động và bạn đã sử dụng Qdrant để tìm kiếm 5 câu trả lời có độ tương đồng cao nhất với truy vấn "Một tín chỉ được tính tương đương bao nhiêu giờ học". Sau khi lấy được 5 kết quả tốt nhất, bạn có thể rerank những kết quả này bằng một mô hình fine-tuned (chẳng hạn như BERT) để đảm bảo thứ tự kết quả phản ánh chính xác hơn về tính liên quan với câu hỏi.
Note
Ở đây mình note lại kiến thức khi tham khảo các bình luận tại facebook
- Nếu bạn chỉ cần kết quả tìm kiếm đơn giản, không cần phải rerank thêm, vì cosine similarity đã đủ để chọn lựa các kết quả tốt nhất.
- Nếu bạn muốn tối ưu hoặc cải thiện chất lượng kết quả, rerank có thể giúp bạn đưa ra các kết quả chính xác hơn, đặc biệt khi sử dụng các mô hình học sâu hoặc phương pháp học máy khác để đánh giá độ liên quan và chất lượng của các kết quả.
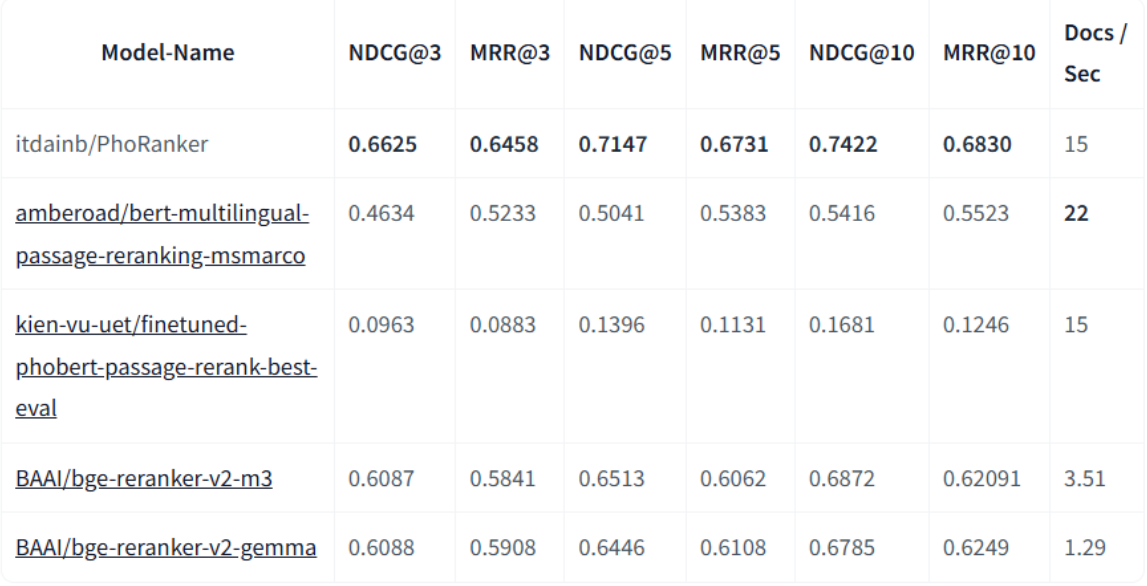
So sánh đánh giá các model rerank
Dưới đây là bảng so sánh rerank model
Link post Nguyễn Bá đại
Ở đây có nói các mô hình rerank để đánh giá và so sánh nó
Embedding model tiếng việt
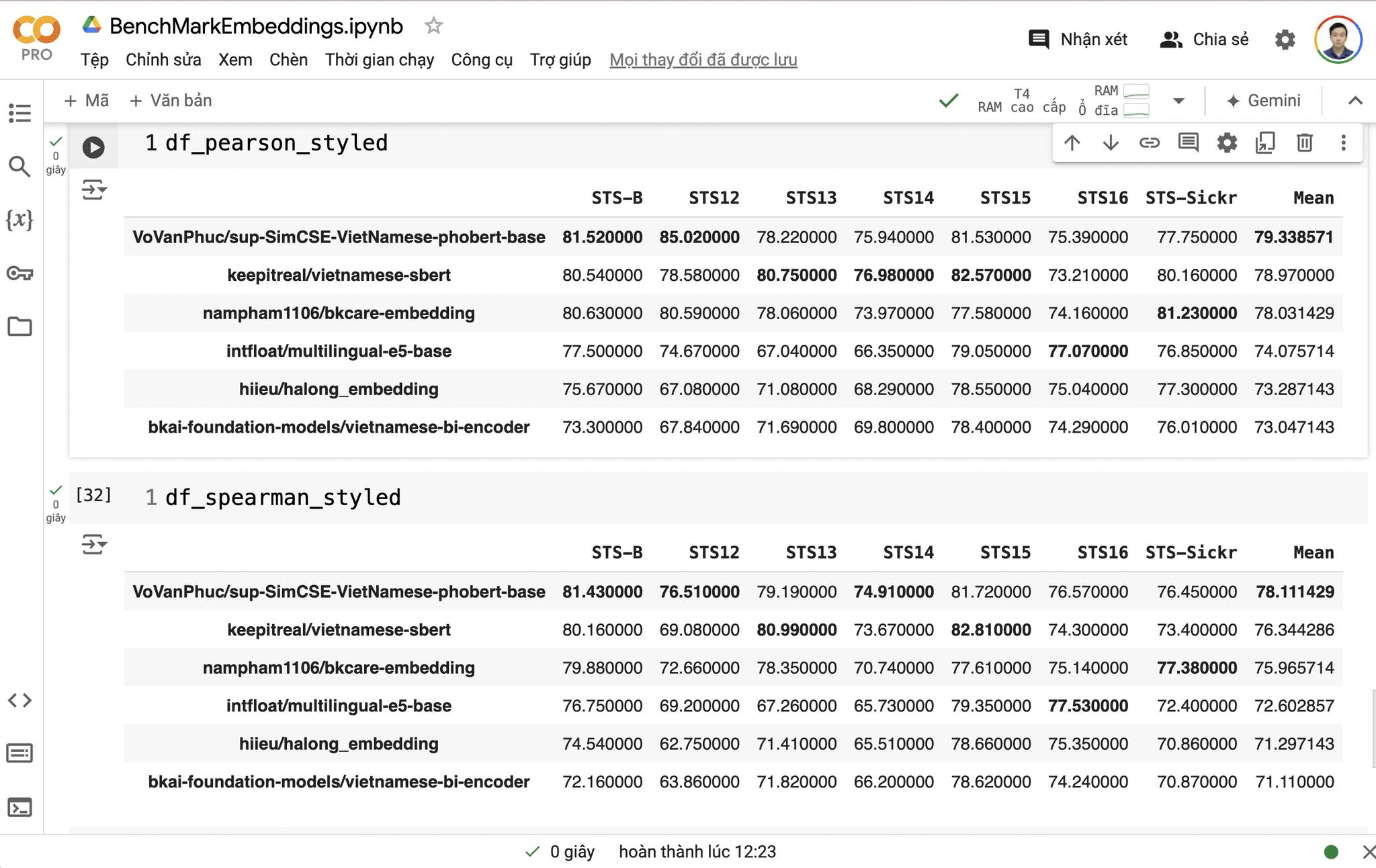
- Đây là benchmark embedding năm 2024 của bài post của anh Bá ngọc
- Đây là nguồn tham khảo để mình dùng embedding model
- Tuy nhiên trong đây thì nó sẽ có hạn chế là xem token size. Hay là số lượng mà input đầu vào của model có thể nhận
Link
- Link bài viết anh Bá ngọc
- Colab
- Thang Nguyen Chien
- Theo ảnh thì là cái VoVanPhuc/sup-SimCSE-VietNamese-phobert-base còn em hay dùng cái keepitreal/vietnamese-sbert
- Vietnamese-sbert
- Halong embedding