Reinforcement Learning Human Feedback - RLHF
3.1 Mô hình GPT:
Các mô hình GPT là một họ các mô hình ngôn ngữ được phát triển bởi OpenAI. Chúng được xây dựng dựa trên kiến trúc transformer, đã chứng minh được tính hiệu quả cao trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên (NLP).
OpenAI họ đã sử dụng kết hợp cả Supervised Learning (học giám sát) và Reinforment Learning (học tăng cường) để tinh chỉnh (fine-tune) ChatGPT, nhưng Reinforcement Learning mới là thành phần làm cho ChatGPT trở nên độc đáo hơn tất cả. Kỹ thuật cụ thể được gọi là Reinforcement Learning from Human Feedback (RLHF), tức là học tăng cường từ những dữ liệu feedback của con người, sử dụng vòng lặp feedback của con người trong quá trình huấn luyện để giảm thiểu việc đưa ra các phản hồi có hại, không trung thực hay là sai lệch tri thức.
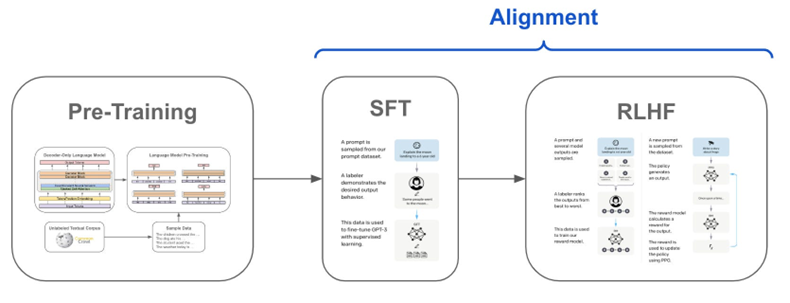
3.2 Capability vs Alignment trong LLMs
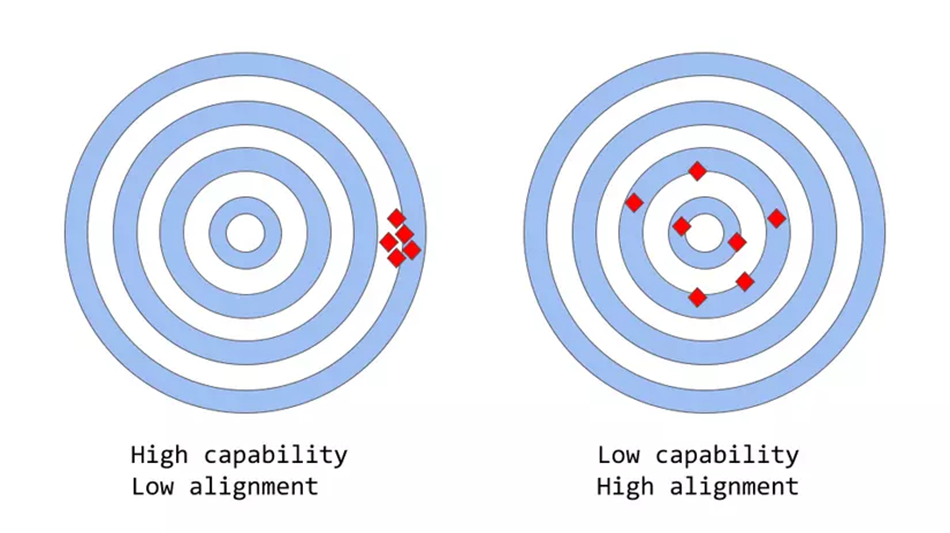
Khái niệm Capability đề cập tới khả năng của một model để thực hiện một hoặc nhiều task cụ thể. Khả năng của một model cụ thể được đánh giá bởi khả năng tối ưu objective-function (hàm tối ưu/ hàm mục tiêu) của nó tốt như thế nào? Ví dụ như, một model được thiết kế để dự đoán giá của thị trường chứng khoán phải có một hàm mục tiêu nào đó đo được độ chính xác các dự đoán của model. Nếu model có khả năng dự đoán chính xác sự biến động giá chứng khoán theo thời gian, thì được xem là có khả năng capability cao cho task này.
Alignment liên quan đến việc mô hình có thực hiện đúng những gì chúng ta mong muốn hay không so với những gì nó được huấn luyện để làm. Chúng ta cần hỏi liệu các hàm mục tiêu trong quá trình huấn luyện có phù hợp với ý định của mình không, và hành vi của mô hình có đáp ứng kỳ vọng của con người không? Ví dụ, khi xây dựng một model phân loại chim, chúng ta có thể dùng log loss làm hàm mục tiêu, nhưng mục tiêu cuối cùng là đạt độ chính xác cao. Điều này có thể dẫn đến model có capability cao nhưng accuracy kém, vì log loss không hoàn toàn tương quan với accuracy trong các nhiệm vụ phân loại.
Các LLMs chẳng hạn như GPT3, BLOOM, PaLM, ... được huấn luyện trên một lượng rất lớn dữ liệu text từ internet và có khả năng sinh văn bản giống như con người, nhưng không phải lúc nào LLMs cũng sinh ra được đầu ra như kỳ vọng của con người hoặc có tính chính xác. Trong thực tế, hàm mục tiêu của chúng là phân phối xác suất trên các chuỗi từ (word sequences) hoặc trên chuỗi token (token sequences) mà cho phép dự đoán chính xác từ tiếp theo trong chuỗi.

Mặc dù những model phức tạp này được huấn luyện trên lượng dữ liệu khổng lồ đã trở nên cực kỳ hiệu quả trong vài năm gần đây, nhưng khi được sử dụng trong các hệ thống sản phẩm thực tế mà giúp cuộc sống con người trở nên dễ dàng hơn thì chúng thường không đạt được khả năng này. Một số vấn đề alignment trong LLMs thường thấy rõ ở dạng:

Các nhà nghiên cứu hay các nhà phát triển họ đang nghiên cứu các hướng khác nhau để giải quyết vấn đề alignment trong LLMs. ChatGPT dựa trên GPT-3 là 1 LLMs nhưng đã được huấn luyện thêm bằng cách sử dụng feedback của con người để làm cho quá trình learning của model với mục đích cụ thể là giảm thiểu được các vấn đề về misalignment. Cụ thuật cụ thể đó được gọi là Reinforcement learning from Human Feedback (Học Tăng cường từ Phản hồi của người dùng). ChatGPT là trường hợp đầu tiên sử dụng kỹ thuật này cho model được đưa vào sản phẩm.
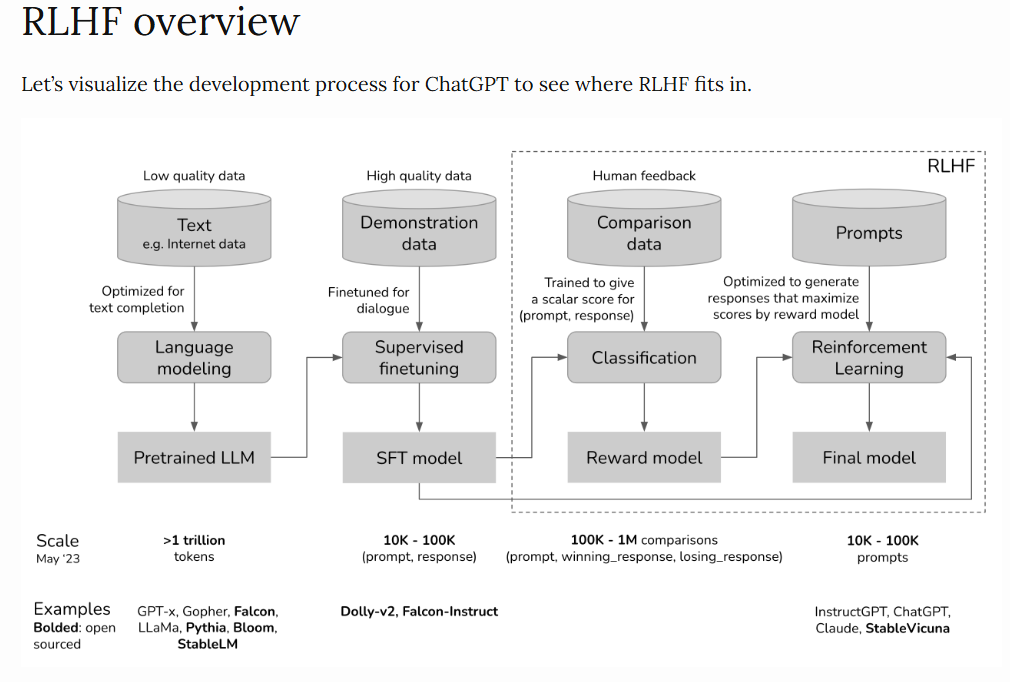
3.3 Học Tăng cường từ Phản hồi của người dùng
Ý tưởng kỹ thuật này xuất phát từ nhu cầu cải thiện đánh giá chất lượng văn bản sinh ra từ các mô hình ngôn ngữ. Trước đây, các mô hình chủ yếu sử dụng loss function hoặc các chỉ số như BLEU và ROUGE để so sánh output với mẫu do con người tạo ra. Tuy nhiên, vì ngôn ngữ đa dạng và phức tạp, việc sử dụng phản hồi của người dùng để đánh giá và tối ưu hóa mô hình đã dẫn đến sự ra đời của RLHF.
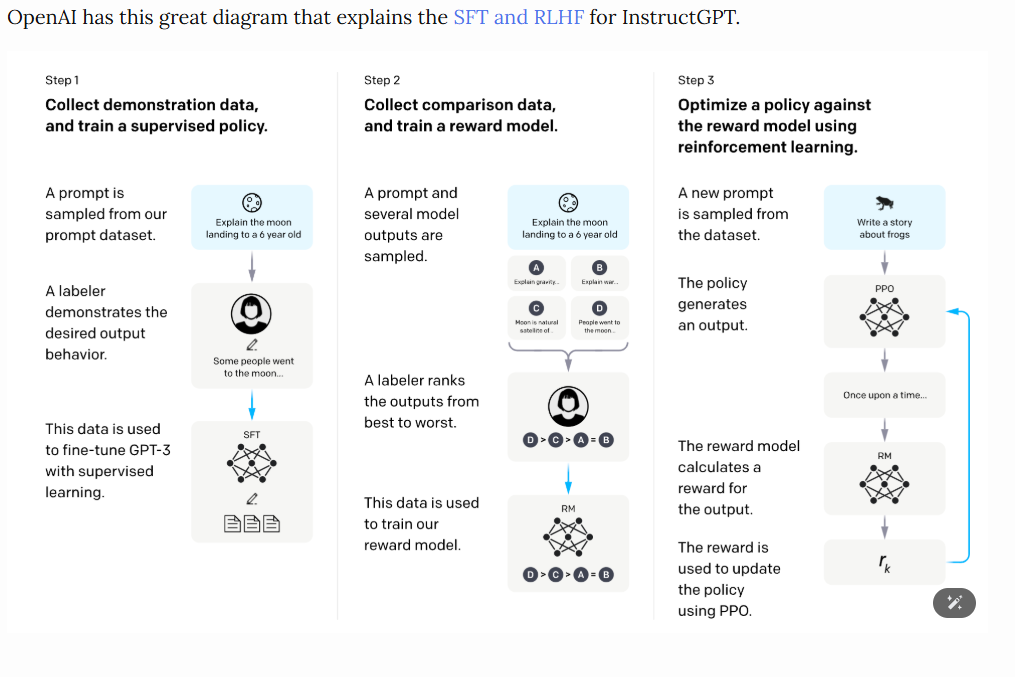
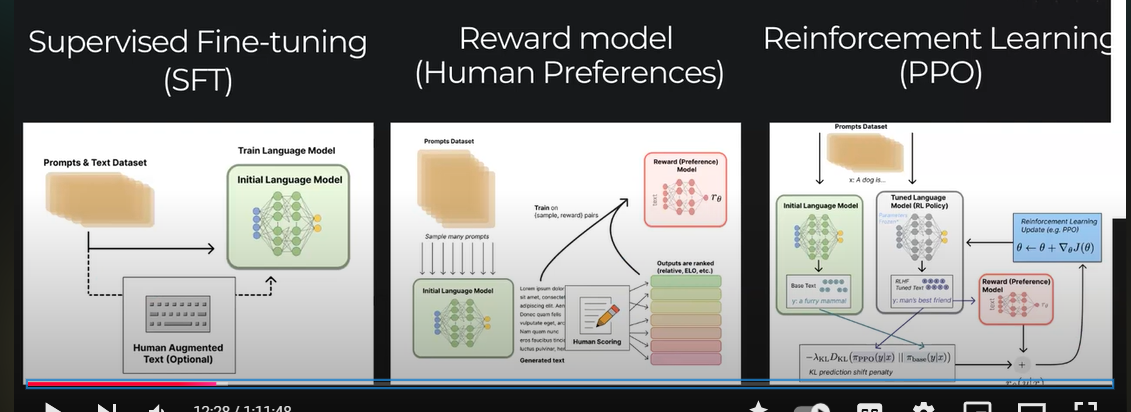
RLHF gồm 3 bước chính:
- Supervised fine-tuning
- Thu thập dữ liệu và huấn luyện một reward model.
- Proximal Policy Optimization (PPO)
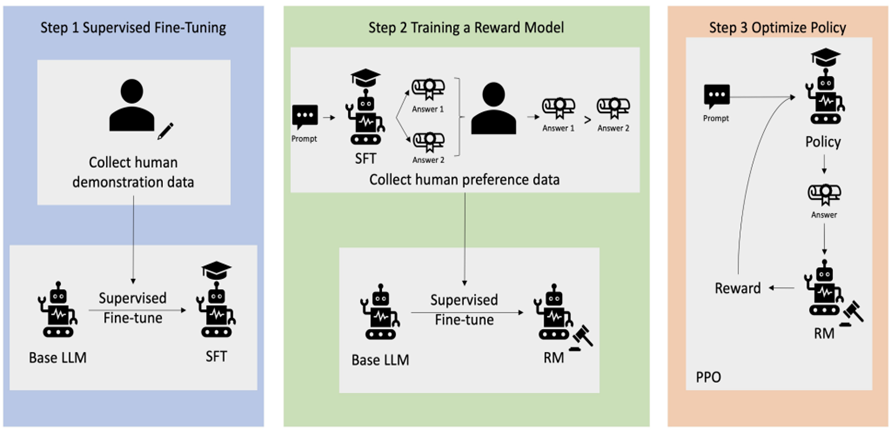
3.3.1 Supervised fine-tuning
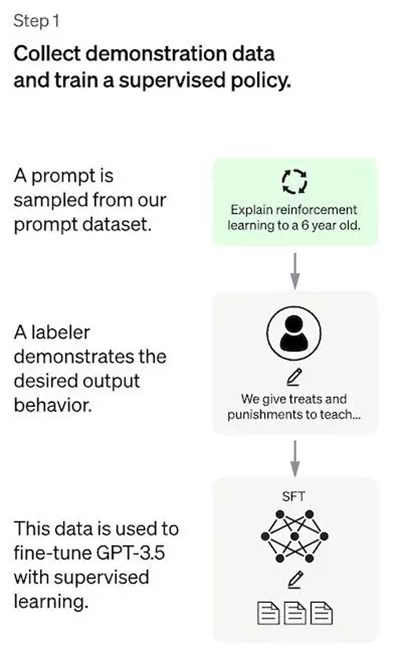
Bước đầu tiên là thu thập hoặc xây dựng bộ dữ liệu minh họa (demonstration data) để huấn luyện mô hình chính sách có giám sát. Bộ dữ liệu này giúp mô hình học các mẫu ngôn ngữ, hiểu ngôn ngữ chính xác hơn và làm quen với các dạng nhiệm vụ như phân loại, trích xuất, hỏi đáp, sinh văn bản,... Bộ dữ liệu càng đa dạng, mô hình càng học tốt và đưa ra phản hồi chính xác.
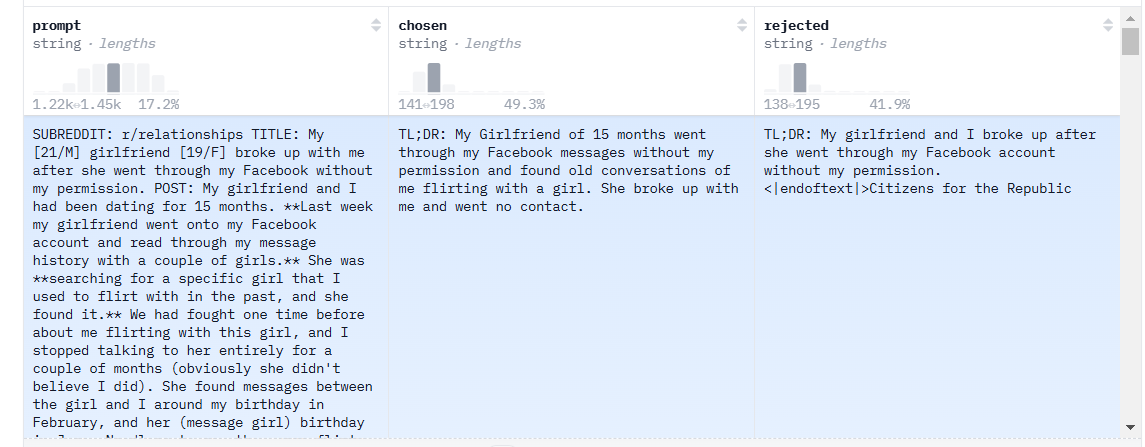
- Thu thập dữ liệu: Một danh sách các prompt được chọn lọc và một nhóm người gán nhãn sẽ viết phản hồi cho các prompt đó. ChatGPT sử dụng hai nguồn prompt: từ các gán nhãn viên và nhà phát triển, và từ các yêu cầu của cộng đồng OpenAI. Do quá trình này tốn kém và chậm, chỉ một lượng nhỏ dữ liệu chất lượng cao (~12-15k điểm dữ liệu) được thu thập để tinh chỉnh mô hình ngôn ngữ lớn (LLM).
- Lựa chọn mô hình: ChatGPT sử dụng LLM đã được huấn luyện trước như GPT-3 hoặc các biến thể của nó như GPT-3.5, text-davinci-003 để tinh chỉnh.
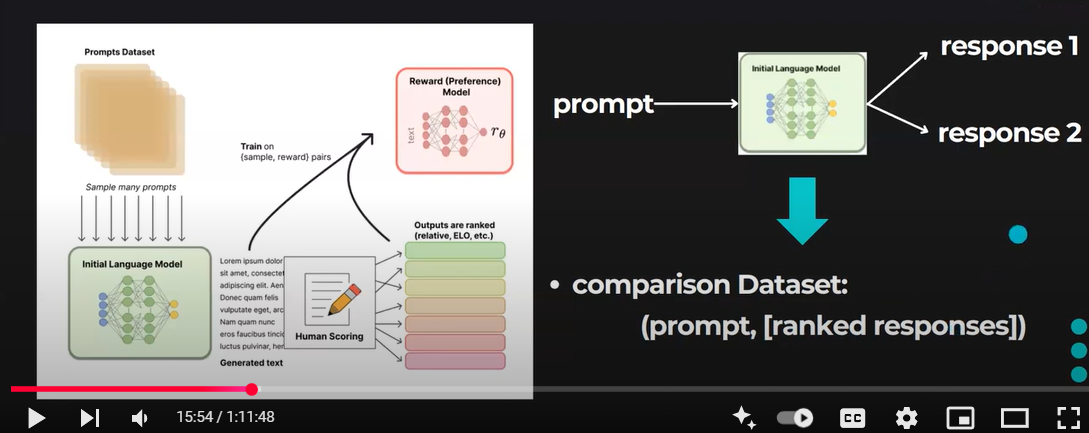
Do giới hạn về số lượng dữ liệu, mô hình SFT sau bước này có khả năng sinh văn bản nhưng vẫn gặp vấn đề về misalignment. Vấn đề của học có giám sát là chi phí mở rộng bộ dữ liệu rất cao. Để khắc phục, thay vì yêu cầu người gán nhãn tạo ra bộ dữ liệu có giám sát lớn, tốn thời gian và chi phí, chiến lược hiện tại là để họ xếp hạng các đầu ra khác nhau của mô hình SFT để tạo ra mô hình thưởng (Reward model).
3.3.2 Thu thập dữ liệu và huấn luyện Reward model
Việc tạo ra một Reward model (RM), hay còn gọi là preference model, là bước quan trọng trong nghiên cứu RLHF, giúp tạo ra sự khác biệt so với các kỹ thuật đánh giá văn bản trước đây. Mục tiêu là tối ưu hóa reward function trong bài toán RL.
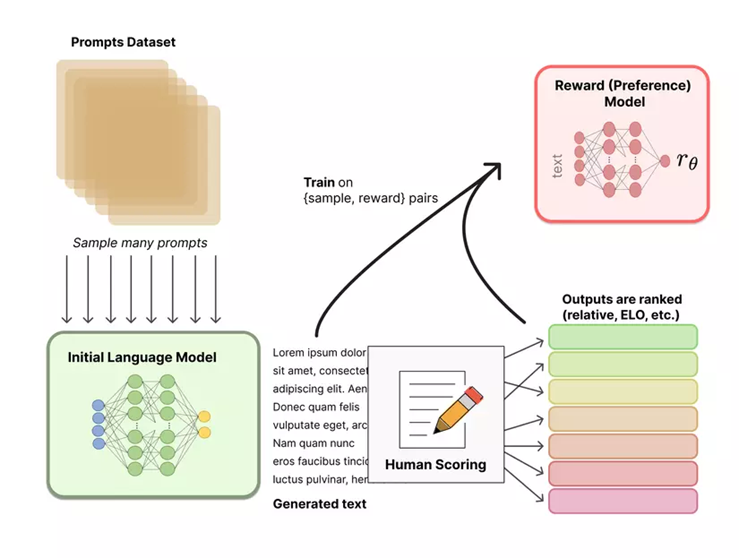
Cách hoạt động như sau:
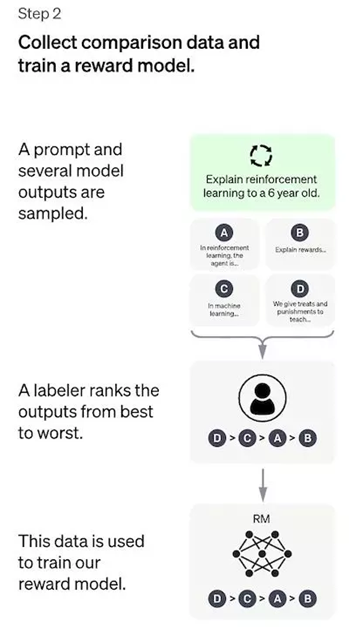
- Một list các prompts được lựa chọn và SFT model sinh ra nhiều outputs (candidates), thường là từ 4 -> 9 cho mỗi prompt.
- Những người gán nhãn họ sẽ ranking các outputs từ score cao tới thấp. Score càng cao thì sẽ càng giống với kỳ vọng của con người. Kết quả sẽ thu được một bộ dữ liệu mới, trong đó thứ tự ranking là nhãn. Kích thước của bộ dữ liệu này có thể gấp khoảng 10 lần so với dữ liệu ở bước 1 được huấn luyện cho SFT model.
- Bộ dữ liệu mới này được sử dụng để huấn luyện reward model (RM). Model này lấy đầu vào là các outputs của SFT model và ranks chúng theo thứ tự kỳ vọng của con người.
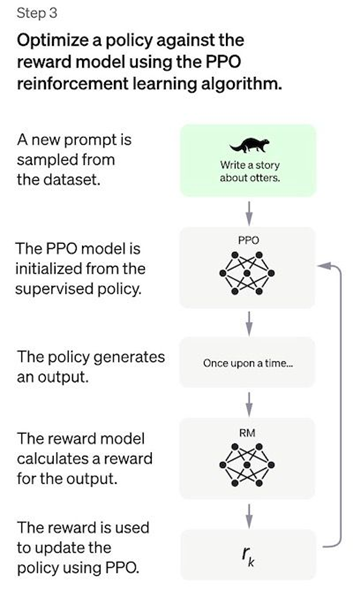
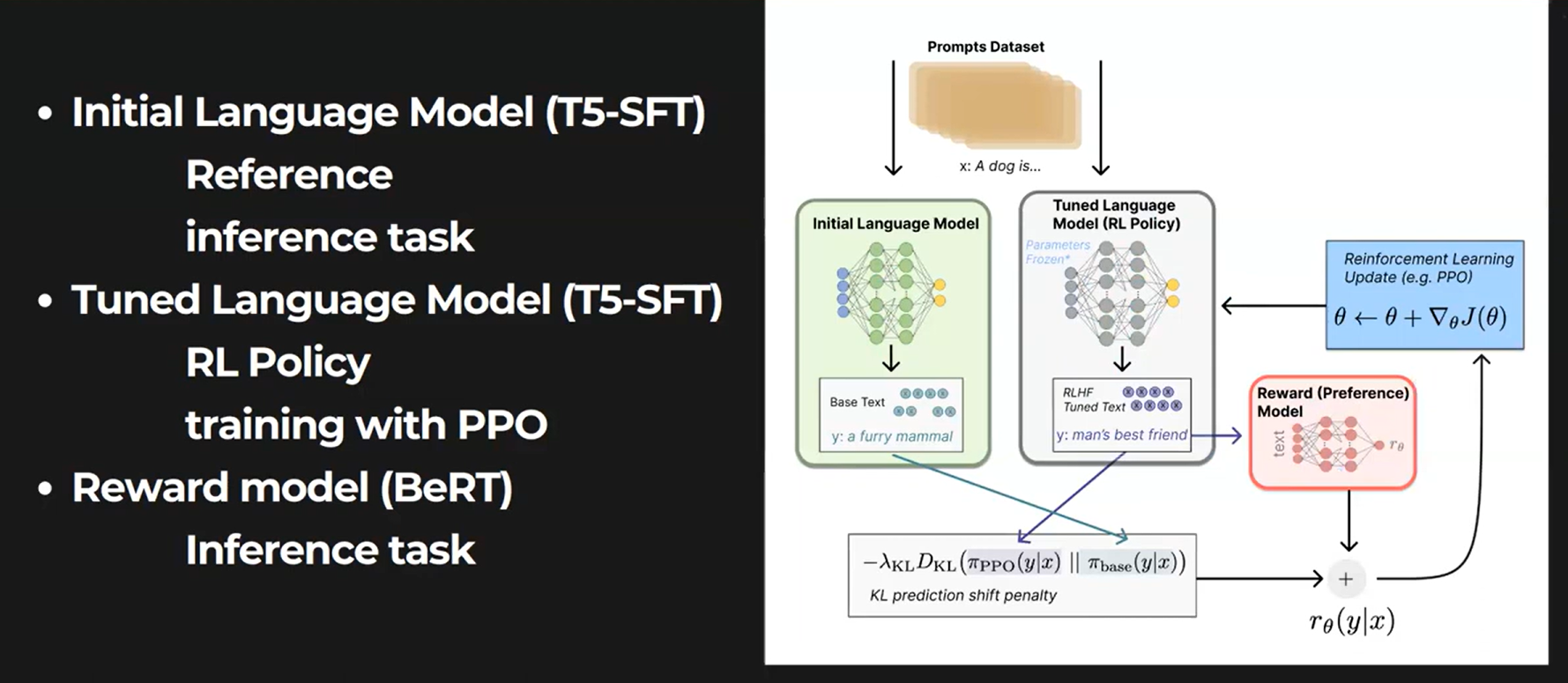
3.3.3 Proximal Policy Optimization (PPO)
Reinforcement Learning (RL) được sử dụng để fine-tune chính sách SFT bằng cách tối ưu hóa reward model, với thuật toán Proximal Policy Optimization (PPO). Mô hình sau khi fine-tune được gọi là PPO model.
PPO là gì? PPO là thuật toán "on-policy" trong học tăng cường, liên tục cập nhật chính sách dựa trên hành động và phần thưởng hiện tại. Nó sử dụng tối ưu hóa vùng tin cậy để đảm bảo thay đổi chính sách ổn định, tránh cập nhật quá lớn gây mất ổn định. PPO cũng dùng hàm giá trị và hàm lợi thế để ước tính và điều chỉnh chính sách dựa trên lợi nhuận kỳ vọng.
Trong bước này, mô hình PPO được khởi tạo từ mô hình SFT, và hàm giá trị được khởi tạo từ mô hình thưởng. Môi trường là môi trường bandit, đưa ra một gợi ý ngẫu nhiên và yêu cầu phản hồi. Dựa vào gợi ý và phản hồi, nó tạo ra phần thưởng và kết thúc phiên. Một hình phạt KL per-token được thêm vào từ mô hình SFT ở mỗi token để giảm thiểu việc tối ưu hóa quá mức mô hình thưởng.