Chuỗi thời gian - Time series
CHƯƠNG 1 – Giới thiệu về chuỗi thời gian
1. Giới thiệu:
1.1 Định nghĩa chi tiết:
Chuỗi thời gian là một tập hợp các quan sát {xt} được ghi lại tại những thời điểm cụ thể t. Các quan sát này thường được sắp xếp theo thứ tự thời gian và có thể là liên tục (đo lường tại mọi thời điểm) hoặc rời rạc (đo lường tại các khoảng thời gian cụ thể).
Công thức toán học: {xt : t ∈ T} Trong đó:
● xt là giá trị quan sát tại thời điểm t
● T là tập hợp các chỉ số thời gian
1.2. Các thành phần của chuỗi thời gian:
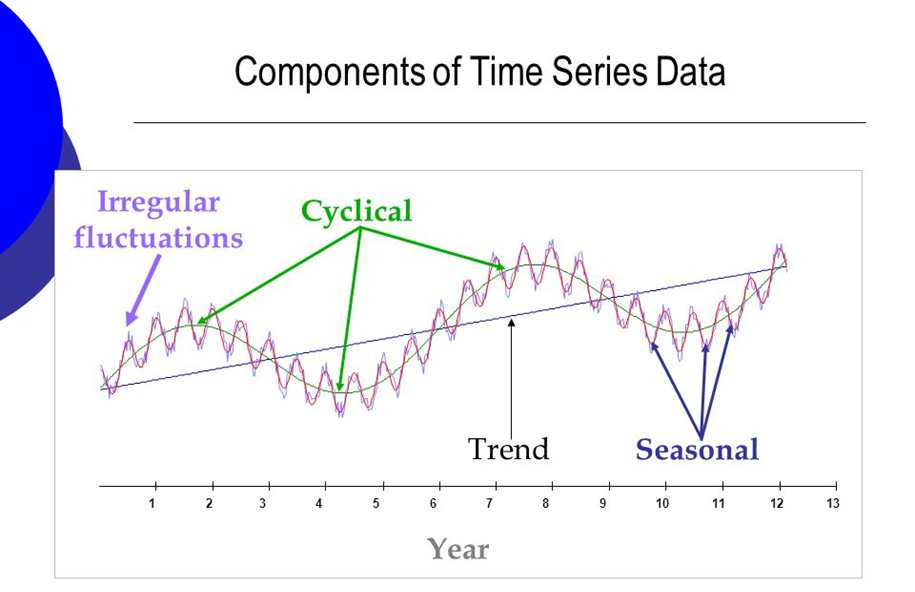
Hình 1: Thành phần của chuỗi thời gian
1.2.1 Xu hướng (Trend):
Đề cập đến hướng di chuyển của dữ liệu qua thời gian, có thể là tăng lên hoặc giảm đi. Điều này thường được nhận biết dựa trên độ dốc của đồ thị biểu diễn dữ liệu.
Một số xu hướng phổ biến của Time Series data:
● Upward Trend: dữ liệu có xu hướng tăng theo thời gian
● Downward Trend: dữ liệu có xu hướng giảm theo thời gian
● Horizontal Trend: Dữ liệu duy trì ổn định hoặc biến đổi rất ít theo thời gian.
● Damped Trend: Dữ liệu giảm dần theo thời gian, nhưng tốc độ giảm đi chậm dần.
● Non-linear Trend: Dữ liệu biến đổi không tuân theo một mô hình tuyến tính đơn giản mà có các biến đổi phức tạp hơn, bao gồm cả sự tăng, giảm, hoặc thay đổi không đồng đều, đột biến theo thời gian (VD: dữ liệu biến đổi theo đồ thị hình sin, cos, hàm số mũ ....)
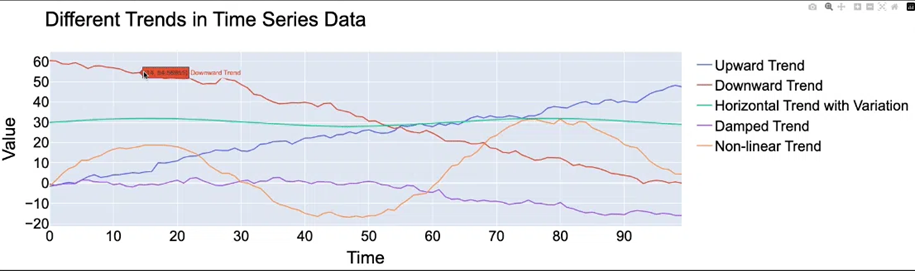
Hình 2: Xu hướng của time series data
1.2.2 Chu kỳ (Cycle):
Tính chu kỳ trong dữ liệu chuỗi thời gian đề cập đến những biến động lên xuống lặp lại, hoặc những thay đổi định kỳ, có thể kéo dài trong nhiều năm và chuyển từ giai đoạn này qua giai đoạn khác. Thường sử dụng phương pháp phân tích phổ hoặc biến đổi Fourier.
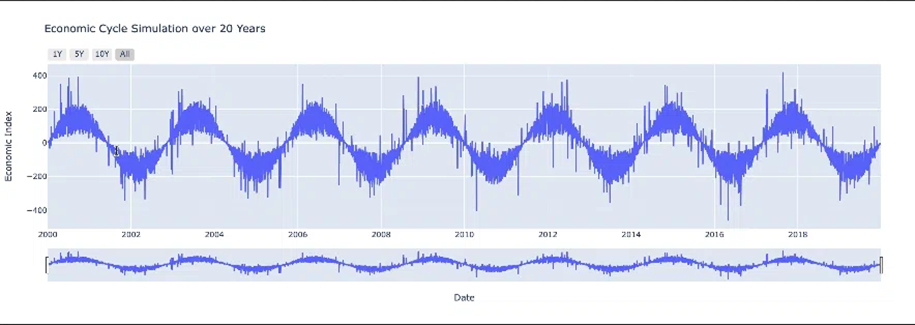
Hình 3: Chu kỳ của time series data_
1.2.3 Mùa vụ (Seasonality):
Tính mùa vụ trong dữ liệu chuỗi thời gian đề cập đến các biến động tăng hoặc giảm mà diễn ra đều đặn và lặp lại trong một khoảng thời gian.
Một số tính mùa vụ phổ biến khi phân tích Time Series data:
● Holiday Seasonality: Sự thay đổi này thường được gây ra bởi các sự kiện đặc biệt như ngày lễ, sự kiện đặc biệt nào đó. Ví dụ: Doanh số bán hàng tăng mạnh vào dịp cuối năm gần Tết.
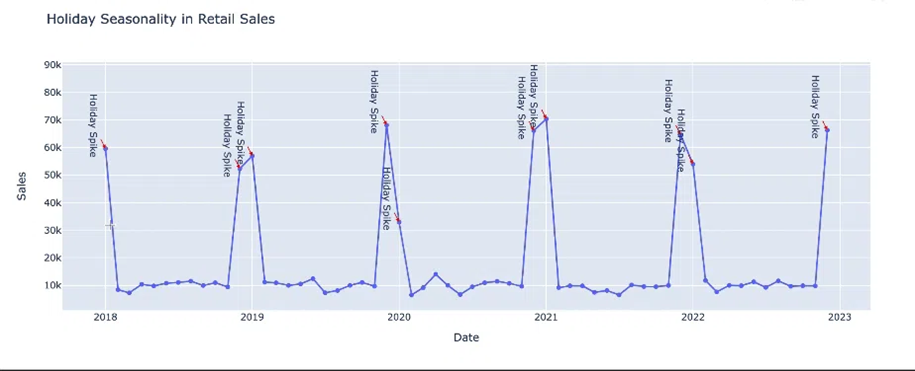
Hình 3: Holiday Seasonality
● Weekly Seasonality: Sự thay đổi lặp lại trong khoảng thời gian 7 ngày. Ví dụ: số lượng vé xem phim tại các rạp tăng mạnh vào các dịp cuối tuần.
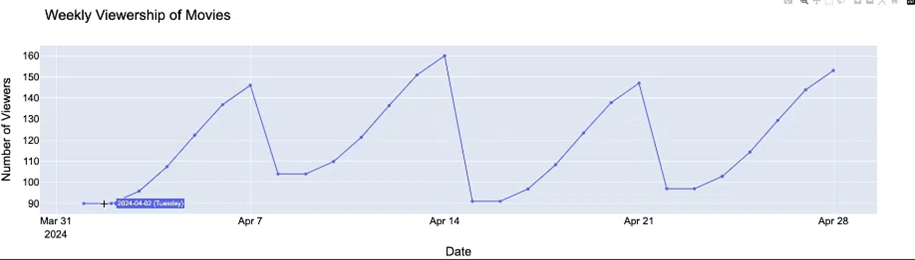
Hình 4: Weekly Seasonality
● Monthly Seasonality: Sự thay đổi lặp lại trong khoảng thời gian 30 hoặc 31 ngày.
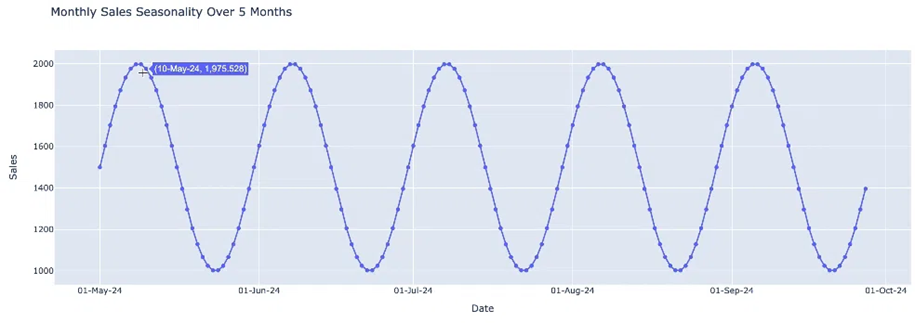
Hình 5: Monthly Seasonality
● Annual Seasonality: Sự thay đổi lặp lại trong khoảng một năm. Chẳng hạn như số lượng du khách tăng đột ngột vào các tháng hè mỗi năm.
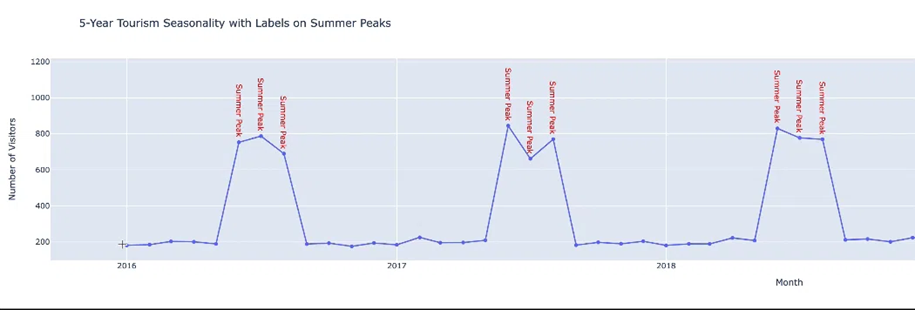
Hình 6: Annual Seasonality
1.2.3 Irregular (hay còn gọi là noise):
- Sự bất thường trong dữ liệu chuỗi thời gian đề cập đến những sự thay đổi bất thường của dữ liệu, xảy ra một cách ngẫu nhiên, có thể trái ngược hoàn toàn với các dữ liệu trong quá khứ, khó có thể giải thích và không dự đoán được trước.
Sự bất thường này có thể do sự sai sót trong đo lường dữ liệu, hoặc những sự kiện bất ngờ diễn ra và có thể vô tình làm ảnh hưởng đến tính chính xác khi đánh giá dữ liệu chuỗi thời gian.
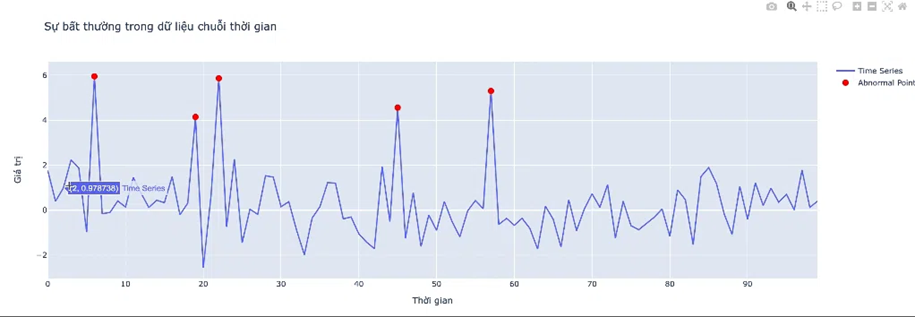
Hình 7: Irregular trong time series data
1.3. Tầm quan trọng của phân tích chuỗi thời gian:
1.3.1 Hiểu về hành vi quá khứ:
● Phát hiện các mẫu và xu hướng trong dữ liệu lịch sử.
● Xác định các yếu tố ảnh hưởng đến biến động của chuỗi.
1.3.2 Dự đoán tương lai:
● Sử dụng thông tin quá khứ để dự báo giá trị tương lai.
● Ước tính độ không chắc chắn trong dự báo.
1.3.3 Đánh giá tác động của sự kiện:
● Phân tích tác động của các can thiệp hoặc thay đổi chính sách.
● Xác định điểm thay đổi cấu trúc trong chuỗi thời gian.
1.3.4 Kiểm soát quá trình:
● Giám sát và điều chỉnh các quá trình sản xuất.
● Phát hiện sớm các bất thường hoặc sai lệch.
1.4. Ứng dụng cụ thể của phân tích chuỗi thời gian:
1.4.1 Dự báo kinh tế và tài chính:
● Dự đoán GDP, tỷ lệ lạm phát, tỷ giá hối đoái.
● Phân tích và dự báo giá cổ phiếu, trái phiếu.
1.4.2 Dự đoán nhu cầu và bán hàng:
● Lập kế hoạch sản xuất và quản lý hàng tồn kho.
● Tối ưu hóa chuỗi cung ứng.
1.4.3 Phân tích thị trường chứng khoán:
● Đánh giá biến động và rủi ro của các công cụ tài chính.
● Xây dựng chiến lược giao dịch tự động.
1.4.4 Dự báo thời tiết:
● Dự đoán nhiệt độ, lượng mưa, tốc độ gió.
● Cảnh báo sớm về các hiện tượng thời tiết cực đoan.
1.4.5 Nghiên cứu dân số:
● Dự báo tăng trưởng dân số và cấu trúc tuổi.
● Phân tích xu hướng di cư.
1.5. Thách thức trong phân tích chuỗi thời gian:
1.5.1 Xử lý dữ liệu thiếu hoặc không đều đặn:
● Phương pháp: Nội suy, ngoại suy, hoặc sử dụng mô hình xử lý dữ liệu không đều.
1.5.2 Đối phó với nhiễu và ngoại lệ:
● Kỹ thuật: Làm mịn dữ liệu, phát hiện và xử lý ngoại lệ.
1.5.3 Xử lý các chuỗi thời gian đa biến:
● Phương pháp: Mô hình VAR (Vector Autoregression), phân tích đồng tích hợp.
1.5.4 Chọn mô hình phù hợp:
● Tiêu chí: AIC (Akaike Information Criterion), BIC (Bayesian Information Criterion).
● Kỹ thuật: Cross-validation với dữ liệu chuỗi thời gian.
1.5.5 Xử lý tính phi tuyến:
● Mô hình: ARCH, GARCH cho biến động, mô hình chuyển đổi trơn.
1.5.6 Đánh giá độ chính xác của dự báo:
Độ đo: MAE (Mean Absolute Error), RMSE (Root Mean Square Error), MAPE (Mean Absolute Percentage Error).
2. Các mô hình chuỗi thời gian phổ biến
2.1 Mô hình tự hồi quy (Autoregressive - AR)
Định nghĩa: Mô hình AR giả định rằng giá trị hiện tại của chuỗi phụ thuộc tuyến tính vào các giá trị trước đó của chính nó cộng với một số nhiễu.
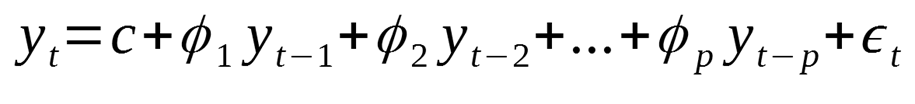
Trong đó:
● yt là giá trị tại thời điểm t
● c là hằng số
● φ1, φ2, ..., φp là các tham số của mô hình
● εt là nhiễu trắng
Ưu điểm:
● Đơn giản và dễ hiểu
● Hiệu quả cho các chuỗi có tương quan tự thân mạnh
Nhược điểm:
● Không thể mô hình hóa các mối quan hệ phi tuyến
● Có thể không phù hợp cho chuỗi có xu hướng hoặc mùa vụ mạnh
2.2 Mô hình trung bình trượt (Moving Average - MA)
Định nghĩa: Mô hình MA giả định rằng giá trị hiện tại của chuỗi phụ thuộc tuyến tính vào các giá trị nhiễu hiện tại và trước đó.
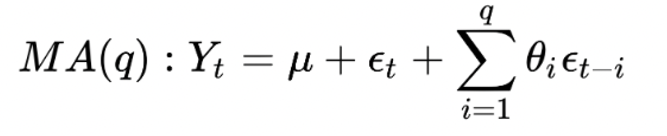
Trong đó:
- μ là giá trị trung bình của chuỗi
- θ1, θ2, ..., θq là các tham số của mô hình
- εt, εt-1, ..., εt-q là các giá trị nhiễu
Ưu điểm:
● Tốt cho việc mô hình hóa các cú sốc ngắn hạn
● Có thể xử lý tốt các nhiễu trong dữ liệu
Nhược điểm:
● Không hiệu quả cho các chuỗi có tương quan tự thân dài hạn
● Có thể khó xác định thứ tự q phù hợp
2.3 Mô hình ARMA (Autoregressive Moving Average)
Định nghĩa: Mô hình ARMA kết hợp cả thành phần AR và MA.
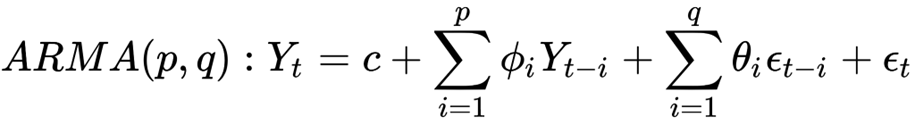
Trong đó:
● yt là giá trị tại thời điểm t
● c là hằng số
● θ1, θ2, ..., θq là các tham số của mô hình
● εt, εt-1, ..., εt-q là các giá trị nhiễu
Ưu điểm:
● Linh hoạt hơn, có thể mô hình hóa nhiều loại chuỗi thời gian khác nhau
● Kết hợp ưu điểm của cả AR và MA
Nhược điểm:
● Phức tạp hơn trong việc ước lượng tham số
● Có thể gặp vấn đề về định danh (identification problem)
2.4 Mô hình ARIMA (Autoregressive Integrated Moving Average)
Định nghĩa: Mở rộng của ARMA, bao gồm cả quá trình lấy sai phân để xử lý tính không dừng của chuỗi.
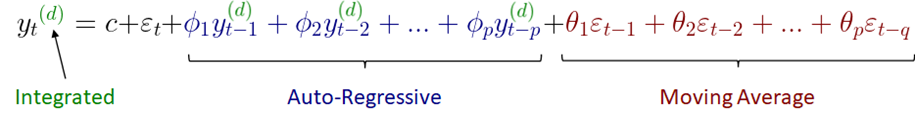
Trong đó:
● yt là giá trị tại thời điểm t
● c là hằng số
● φ1, φ2, ..., φp là các tham số của mô hình
● θ1, θ2, ..., θq là các tham số của mô hình
● εt, εt-1, ..., εt-q là các giá trị nhiễu
Ưu điểm:
● Có thể xử lý chuỗi không dừng
● Linh hoạt, có thể áp dụng cho nhiều loại chuỗi thời gian khác nhau
Nhược điểm:
● Yêu cầu kinh nghiệm trong việc xác định các tham số p, d, q
● Có thể không hiệu quả với chuỗi có tính mùa vụ mạnh
2.5 Các mô hình học sâu cho chuỗi thời gian
2.5.1 Long Short-Term Memory (LSTM)
● Định nghĩa: Một loại RNN đặc biệt có khả năng học các phụ thuộc dài hạn
● Đặc điểm: Sử dụng các cổng (gates) để kiểm soát luồng thông tin
● Ưu điểm: Xử lý tốt vấn đề gradient biến mất, học được các phụ thuộc dài
● Nhược điểm: Phức tạp, cần nhiều dữ liệu để huấn luyện
2.5.2 Recurrent Neural Networks (RNN)
● Định nghĩa: Mạng neural có kết nối vòng lặp, cho phép lưu trữ thông tin
● Đặc điểm: Phù hợp cho dữ liệu chuỗi và dự đoán chuỗi thời gian
● Ưu điểm: Có thể xử lý đầu vào có độ dài thay đổi
● Nhược điểm: Gặp vấn đề gradient biến mất/bùng nổ với chuỗi dài
2.5.3 Multilayer Perceptron (MLP)
● Định nghĩa: Mạng neural tiến tới với nhiều lớp ẩn
● Đặc điểm: Có thể học các mối quan hệ phi tuyến phức tạp
● Ứng dụng trong chuỗi thời gian: Sử dụng cửa sổ trượt để xử lý dữ liệu tuần tự
● Ưu điểm: Đơn giản, linh hoạt
● Nhược điểm: Không có bộ nhớ tích hợp như RNN hoặc LSTM
2.5.4 Feedforward Neural Network (FFNN)
● Định nghĩa: Mạng neural cơ bản nhất, thông tin chỉ di chuyển một chiều
● Đặc điểm: Không có kết nối vòng lặp, mỗi nơ-ron trong một lớp kết nối với tất cả nơ-ron ở lớp tiếp theo
● Ứng dụng trong chuỗi thời gian: Tương tự MLP, sử dụng cửa sổ trượt
● Ưu điểm: Đơn giản, dễ huấn luyện
● Nhược điểm: Không có khả năng tự nhiên để xử lý dữ liệu tuần tự
3. Ứng dụng trong dự đoán giá
3.1. Tổng quan về dự đoán giá
Dự đoán giá là một ứng dụng quan trọng của phân tích chuỗi thời gian, đặc biệt trong lĩnh vực tài chính, kinh tế và kinh doanh. Mục tiêu là sử dụng dữ liệu lịch sử và các yếu tố liên quan để dự báo giá cả trong tương lai.
3.2. Các loại dự đoán giá
3.2.1 Dự đoán ngắn hạn (Short-term forecasting):
● Thời gian: Từ vài giờ đến vài ngày
● Ứng dụng: Giao dịch intraday, quản lý rủi ro ngắn hạn
● Mô hình phù hợp: ARIMA, GARCH, LSTM
3.2.2 Dự đoán trung hạn (Medium-term forecasting):
● Thời gian: Từ vài tuần đến vài tháng
● Ứng dụng: Lập kế hoạch đầu tư, quản lý danh mục đầu tư
● Mô hình phù hợp: SARIMA, VAR (Vector Autoregression), MLP
3.2.3 Dự đoán dài hạn (Long-term forecasting):
● Thời gian: Từ vài tháng đến vài năm
● Ứng dụng: Lập kế hoạch chiến lược, dự báo xu hướng thị trường
● Mô hình phù hợp: Mô hình kinh tế lượng, mô hình cấu trúc, kết hợp với phân tích cơ bản
3.3. Quy trình dự đoán giá
3.3.1 Thu thập và xử lý dữ liệu:
● Nguồn dữ liệu: Dữ liệu lịch sử giá, khối lượng giao dịch, chỉ số kinh tế vĩ mô, tin tức
● Xử lý dữ liệu thiếu: Nội suy, loại bỏ, hoặc thay thế bằng giá trị trung bình
● Chuẩn hóa dữ liệu: Scaling (ví dụ: Min-Max scaling, Z-score normalization)
● Phát hiện và xử lý ngoại lệ: Sử dụng phương pháp IQR (Interquartile Range) hoặc Z-score
3.3.2 Phân tích dữ liệu sơ bộ:
● Kiểm tra tính dừng: Sử dụng kiểm định Augmented Dickey-Fuller (ADF)
● Phân tích thành phần: Xu hướng, chu kỳ, mùa vụ, và thành phần không thường xuyên
● Visualize dữ liệu: Biểu đồ giá, biểu đồ nến, biểu đồ khối lượng
3.3.3 Lựa chọn và xây dựng mô hình:
● Chia dữ liệu: Tập huấn luyện (training set), tập kiểm định (validation set), tập kiểm tra (test set)
● Lựa chọn mô hình: Dựa trên đặc điểm dữ liệu và mục tiêu dự đoán
● Xác định tham số: Sử dụng phương pháp Grid Search hoặc Random Search
● Huấn luyện mô hình: Sử dụng tập huấn luyện
3.3.4 Đánh giá mô hình:
● Độ đo hiệu suất: MAE (Mean Absolute Error), RMSE (Root Mean Square Error), MAPE (Mean Absolute Percentage Error)
● Cross-validation: K-fold cross-validation với điều chỉnh cho dữ liệu chuỗi thời gian
● Kiểm tra tính ổn định: Backtesting trên nhiều khoảng thời gian khác nhau
3.3.5 Tinh chỉnh và cải thiện mô hình:
● Thử nghiệm với các biến đầu vào khác nhau
● Kết hợp nhiều mô hình (Ensemble methods)
● Áp dụng kỹ thuật học sâu nếu có đủ dữ liệu
3.3.6 Triển khai và giám sát:
● Tích hợp mô hình vào hệ thống giao dịch hoặc phân tích
● Giám sát hiệu suất mô hình theo thời gian thực
● Cập nhật và tái huấn luyện mô hình định kỳ
3.4 Ứng dụng cụ thể trong dự đoán giá
3.4.1 Dự đoán giá cổ phiếu:
● Dữ liệu đầu vào: Giá đóng cửa hàng ngày, khối lượng giao dịch, chỉ số thị trường
● Mô hình phổ biến: ARIMA, LSTM, Transformer
● Thách thức: Biến động cao, ảnh hưởng của tin tức và sự kiện bất ngờ
● Kỹ thuật bổ sung: Phân tích kỹ thuật (ví dụ: Moving Averages, RSI)
3.4.2 Dự đoán giá hàng hóa (commodities):
● Dữ liệu đầu vào: Giá spot, futures, tồn kho, sản lượng, nhu cầu
● Mô hình phổ biến: SARIMA (cho tính mùa vụ), VAR (cho tương tác giữa các biến)
● Thách thức: Ảnh hưởng của yếu tố địa chính trị, thời tiết
● Kỹ thuật bổ sung: Phân tích cơ bản về cung-cầu
3.4.3 Dự đoán tỷ giá hối đoái:
● Dữ liệu đầu vào: Tỷ giá lịch sử, chỉ số kinh tế (lạm phát, lãi suất), dữ liệu thương mại
● Mô hình phổ biến: GARCH (cho biến động), RNN (cho phụ thuộc dài hạn)
● Thách thức: Ảnh hưởng của chính sách tiền tệ, sự kiện kinh tế-chính trị toàn cầu
● Kỹ thuật bổ sung: Phân tích sentiment từ tin tức và mạng xã hội
3.4.4 Dự đoán giá bất động sản:
● Dữ liệu đầu vào: Giá bán lịch sử, chỉ số kinh tế vĩ mô, dân số, quy hoạch đô thị
● Mô hình phổ biến: Hồi quy đa biến, Random Forest, Gradient Boosting
● Thách thức: Dữ liệu không đồng nhất, ảnh hưởng của yếu tố địa lý
● Kỹ thuật bổ sung: Phân tích không gian địa lý (GIS)
3.5. Các yếu tố ảnh hưởng đến hiệu suất dự đoán
3.5.1 Chất lượng và số lượng dữ liệu:
● Độ chính xác và đầy đủ của dữ liệu lịch sử
● Tần suất cập nhật dữ liệu (real-time vs. end-of-day)
3.5.2 Độ phức tạp của thị trường:
● Mức độ hiệu quả của thị trường (Efficient Market Hypothesis)
● Sự tương tác giữa các yếu tố vĩ mô và vi mô
3.5.3 Horizon dự đoán:
● Dự đoán ngắn hạn thường chính xác hơn dự đoán dài hạn
● Tích lũy sai số theo thời gian
3.5.4 Sự kiện bất ngờ và tin tức:
● Khả năng phản ứng của mô hình với thông tin mới
● Tích hợp phân tích sentiment và xử lý ngôn ngữ tự nhiên
3.5.5 Kỹ thuật mô hình hóa:
● Lựa chọn mô hình phù hợp với đặc điểm dữ liệu
● Kỹ thuật feature engineering và feature selection
4. Mô tả bài toán và đánh giá các mô hình:
4.1 Mô tả bài toán:
Bài toán của bạn tập trung vào việc dự đoán giá cổ phiếu của công ty UNIQLO (Fast Retailing) dựa trên dữ liệu lịch sử từ tháng 1/2012 đến tháng 1/2017. Dữ liệu bao gồm các thông tin như giá mở cửa, giá cao nhất, giá thấp nhất, giá đóng cửa, khối lượng giao dịch và giá trị giao dịch cổ phiếu. Bạn đã sử dụng phương pháp chuỗi thời gian với cửa sổ trượt 100 ngày để dự đoán giá mở cửa trong tương lai.
Các mô hình đã sử dụng:
● RNN (Mạng nơ-ron hồi quy)
● FFNN (Mạng nơ-ron truyền thẳng)
● MLP (Perceptron đa lớp)
● LSTM (Bộ nhớ dài-ngắn hạn)
Dữ liệu đã được chuẩn hóa và chia thành tập huấn luyện (90%) và tập kiểm tra (10%). Mỗi mô hình được huấn luyện với 100 epoch và kích thước batch là 32.
4.2 Đánh giá các mô hình:
4.2.1 Thời gian huấn luyện và kiểm tra:
RNN và LSTM có thời gian huấn luyện dài nhất, trong khi FFNN và MLP nhanh hơn đáng kể.
Về thời gian kiểm tra, LSTM mất nhiều thời gian nhất, tiếp theo là RNN. FFNN và MLP có thời gian kiểm tra nhanh nhất.
4.2.2 Độ chính xác:
Dựa trên đồ thị MSE và MAE, LSTM có vẻ đạt hiệu suất tốt nhất, với cả MSE và MAE thấp nhất.
RNN đứng thứ hai về hiệu suất, tiếp theo là MLP và cuối cùng là FFNN.
4.2.3. Khả năng học và tổng quát hóa:
Tất cả các mô hình đều cho thấy sự cải thiện trong quá trình huấn luyện, với lỗi giảm dần qua các epoch.
LSTM và RNN có xu hướng bám sát giá thực tế hơn so với FFNN và MLP, đặc biệt là trong việc nắm bắt các biến động ngắn hạn.
4.2.4. Ưu và nhược điểm:
● LSTM: Hiệu suất tốt nhất nhưng tốn nhiều thời gian để huấn luyện và dự đoán.
● RNN: Cân bằng tốt giữa hiệu suất và thời gian tính toán.
● MLP: Nhanh để huấn luyện và dự đoán, nhưng độ chính xác thấp hơn so với LSTM và RNN.
● FFNN: Nhanh nhất để huấn luyện và dự đoán, nhưng có độ chính xác thấp nhất.