Mixture Of Experts
References
Key words
- Dense models - Sparsity , Moe Models
- Gshard
- Router
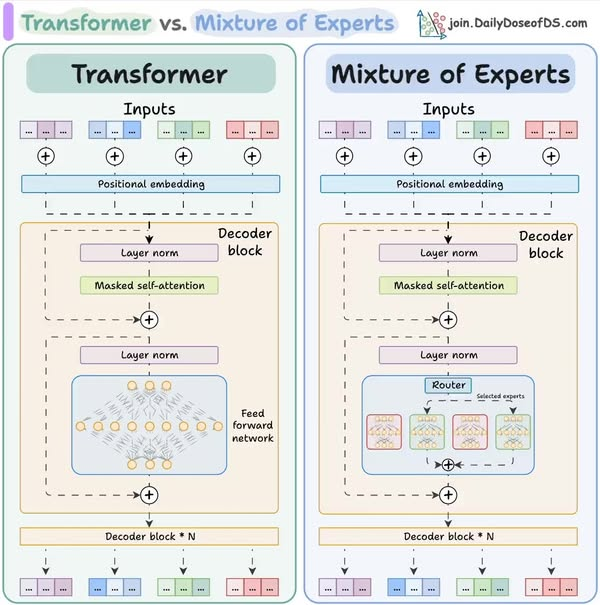
MoE: Tương Lai Của Mô Hình AI Lớn?
Giới Thiệu Về MoE
MoE (Mixture of Experts) là một kiến trúc đột phá trong AI, giúp mô hình trở nên linh hoạt và hiệu quả hơn so với các mô hình dense truyền thống. Các mô hình MoE như Mixtral 8x7B và DeepSeek MoE đang chứng minh rằng chúng vừa nhanh, vừa chất lượng!
Lợi ích của MoE
1. Huấn Luyện Hiệu Quả
MoE giúp giảm thiểu tài nguyên tính toán trong giai đoạn pretraining. Tuy nhiên, quá trình fine-tuning có thể gây overfitting do các experts khó tổng quát hoá.
2. Suy Luận Siêu Tốc
Dù MoE có rất nhiều tham số, nhưng chỉ một phần nhỏ trong số đó được kích hoạt khi suy luận. Việc chọn lọc experts khi xử lý giúp tăng tốc độ so với mô hình dense tương đương.
Thách Thức Của MoE
1. Yêu Cầu Bộ Nhớ Cao
Dù chỉ kích hoạt một phần nhỏ tham số khi suy luận, nhưng tất cả tham số vẫn phải được tải vào RAM. Ví dụ, Mixtral 8x7B dù chỉ dùng 13B tham số khi suy luận nhưng vẫn cần để toàn bộ 47B tham số trong RAM.
2. Phân Phối Experts Không Đồng Đều
- Experts bị under-trained: Một số experts bị lắm đường, không được chọn thường xuyên, dẫn đến việc học không đồng đều. Giải pháp: Thêm nhiễu vào router để tăng tính ngẫu nhiên khi chọn experts.
- Tải không cân bằng: Một số experts có thể bị quá tải, trong khi những experts khác bị nhắc việc. Giải pháp: Giới hạn số token mỗi expert có thể xử lý.
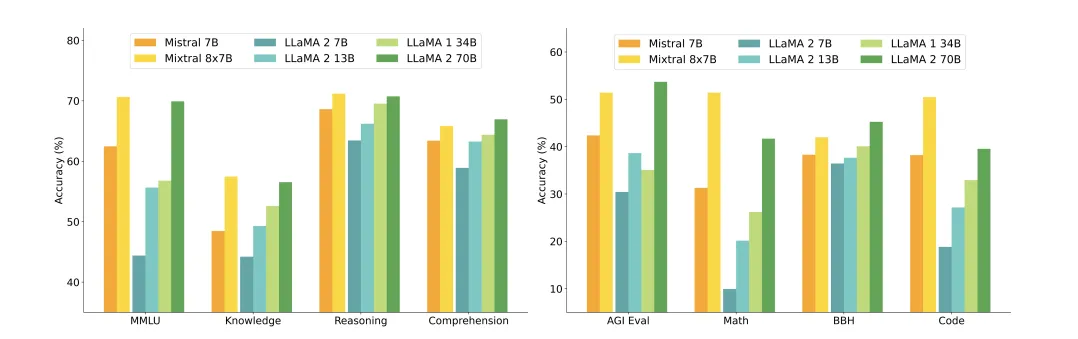
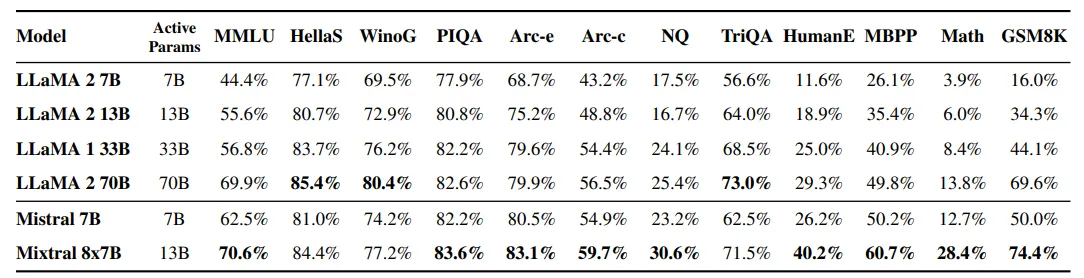
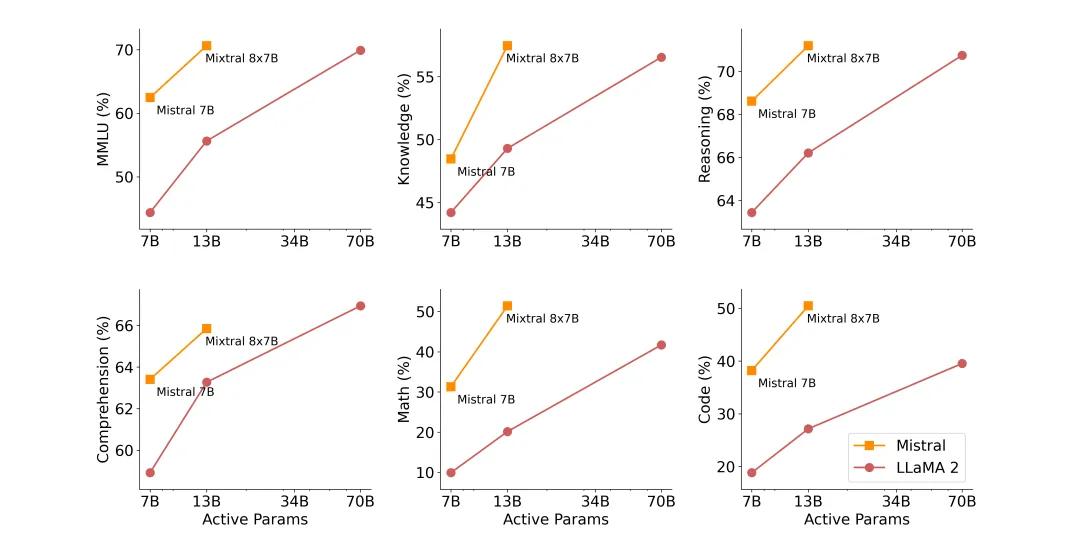
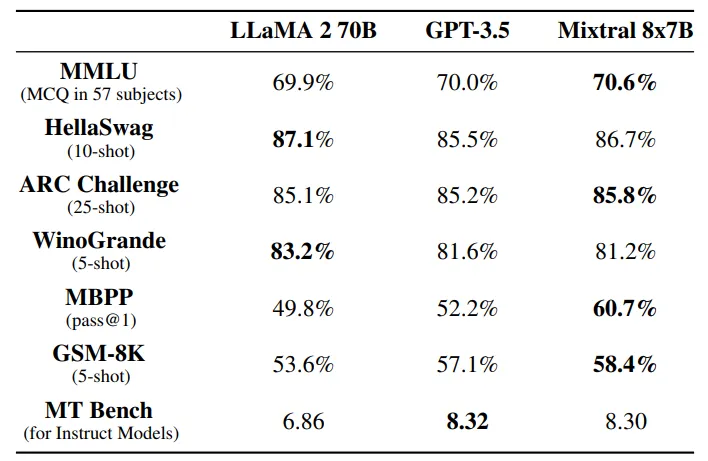
Thực Tế: Mixtral 8x7B vs. DeepSeek MoE
Mixtral 8x7B (Mistral AI)
- Tổng số tham số: 47B, nhưng chỉ dùng 13B khi suy luận.
- Cách hoạt động: Chỉ kích hoạt 2 experts trong 8 experts.
- Hiệu suất: Nhanh hơn 6 lần so với Llama 2 70B.
- Thế mạnh: Toán học, lập trình, đa ngôn ngữ.
DeepSeek MoE
- Chiến lược: Từng tự như Mixtral, tối ưu hóa việc chọn experts.
- Mô hình: DeepSeek 67B, có hàng chục tỷ tham số nhưng rất tiết kiệm tài nguyên.
- Ứng dụng: Phân tích dữ liệu, AI chatbot.
Kết Luận
MoE mang lại bước nhảy vọt trong AI, kết hợp giữa hiệu suất và tính linh hoạt. Tuy nhiên, những thách thức về bộ nhớ và tải cân bằng cần được giải quyết. Các mô hình như Mixtral 8x7B và DeepSeek MoE chứng tỏ rằng MoE là hướng đi đáng chú ý trong tương lai!
1. Công thức cơ bản của MoE Gating Network
Mô hình Mixture of Experts (MoE) sử dụng một mạng gating (G) để quyết định xem phần nào của đầu vào sẽ được gửi đến chuyên gia nào (E). Công thức chính:
- (G(x)) là gating function, trả về trọng số cho từng chuyên gia ( Ei).
- ( E_i(x)) là hàm của chuyên gia thứ ( i ) xử lý đầu vào ( x ).
- (y) là đầu ra cuối cùng, được tính bằng tổng có trọng số của các đầu ra từ các chuyên gia.
👉 Hiểu đơn giản: Gating network ( G(x) ) quyết định tỷ lệ đầu vào ( x ) được gửi đến các chuyên gia ( E_i ).
2. Gating Function Truyền Thống (Softmax)
Trong cách tiếp cận truyền thống, gating function chỉ đơn giản là một mạng nơ-ron nhỏ với hàm Softmax:
- ( W_g ) là trọng số học được của mạng gating.
- Softmax đảm bảo tổng các trọng số ( G(x)_i ) của các chuyên gia luôn bằng 1, nghĩa là đầu vào được chia tỷ lệ hợp lý giữa các chuyên gia.
👉 Hiểu đơn giản: Softmax giúp chọn chuyên gia nào được kích hoạt và với tỷ lệ bao nhiêu.
3. Noisy Top-k Gating (Cơ chế chọn lọc k chuyên gia)
Shazeer et al. đề xuất một phương pháp gating khác gọi là Noisy Top-k Gating, giúp làm cho quá trình chọn chuyên gia đa dạng hơn và giảm chi phí tính toán bằng cách chỉ chọn k chuyên gia có giá trị cao nhất thay vì dùng tất cả.
Bước 1: Thêm nhiễu vào tín hiệu gating
- Wnoise là trọng số của thành phần nhiễu, giúp tăng tính đa dạng trong quá trình chọn chuyên gia.
- StandardNormal tạo nhiễu ngẫu nhiên theo phân phối chuẩn.
- Softplus đảm bảo giá trị nhiễu không bị âm quá nhiều, giúp giữ sự ổn định.
👉 Hiểu đơn giản: Thêm một lượng nhiễu điều chỉnh được vào trọng số gating để tránh overfitting và giúp mô hình tổng quát hóa tốt hơn.
Bước 2: Giữ lại chỉ ( k ) chuyên gia có trọng số cao nhất
- Chỉ giữ lại ( k ) giá trị lớn nhất của ( H(x) ), đặt tất cả các giá trị khác thành ( -\infty ) (để Softmax sau này gần như bằng 0 cho chúng).
- Điều này giúp giảm số chuyên gia hoạt động, tiết kiệm tính toán.
👉 Hiểu đơn giản: Chỉ kích hoạt một số chuyên gia tốt nhất thay vì tất cả.
Bước 3: Áp dụng Softmax chỉ trên các giá trị được giữ lại
- Sau khi chỉ giữ lại ( k ) chuyên gia, ta chuẩn hóa lại trọng số bằng Softmax.
- Điều này đảm bảo tổng trọng số phân bổ giữa các chuyên gia vẫn hợp lý.
👉 Hiểu đơn giản: Tinh chỉnh trọng số cuối cùng bằng Softmax sau khi đã lọc ra các chuyên gia tốt nhất.
4. Lợi ích của Noisy Top-k Gating
✅ Giảm chi phí tính toán: Vì chỉ có ( k ) chuyên gia được kích hoạt thay vì tất cả.
✅ Cải thiện tính đa dạng: Việc thêm nhiễu giúp mô hình học cách chọn chuyên gia một cách linh hoạt hơn.
✅ Tăng hiệu suất học: Ban đầu, người ta nghĩ rằng chọn 1 chuyên gia duy nhất là đủ, nhưng thực tế cần ít nhất 2 chuyên gia để mạng có thể học cách phân loại đầu vào hợp lý.
🚀 Tóm lại:
- Mạng Gating giúp quyết định dữ liệu nào sẽ được xử lý bởi chuyên gia nào.
- Cách đơn giản nhất là
Evaluation