Project CNTT
Guiding assistant for Vietnamese university admissions powered by Advanced RAG
The University Admission Assistant is an AI-powered system designed to support admission inquiries for 15 universities in Ho Chi Minh City. The system leverages Retrieval-Augmented Generation (RAG) techniques to enhance query responses by integrating structured data retrieval with generative AI models. This ensures accurate and context-aware answers to users' admission-related questions.
Link
- Github: https://github.com/HoangVuSnape/UNI_HCM_AI
- Web deploy: https://huggingface.co/spaces/HoangVuSnape/TuyenSinh_v2
- Link dataset: https://drive.google.com/drive/folders/1iPG2Sw53wbe7uVmyQZwGQtZeMc4Q4YmF
- ../../02_Tech_Second_Brain/AI_Core/Fundamentals/RAG Advance
Architecture System
This project presents two versions of an agent system, comparing their architecture, tools, and functionalities. The improvements in Version 2 result from extensive testing and experimentation.
Version 1
The initial system employs an embedding-based approach using recursive splitting and vector search for efficient querying. It includes the following tools:
- Time: Provides the current time in Vietnamese.
- getRetrieval: Inspired by self-RAG, retrieves relevant information.
- Websearch: Conducts web searches for additional insights.
- getScore: Converts queries into SQL and returns relevant results based on scoring.
Version 2 (Final Version)
Significant enhancements were made, including:
- Semantic Chunking: Improved data segmentation for better understanding.
- Hybrid Search: Combines multiple search strategies for enhanced accuracy.
- Watch more Rerank_EmbeddingModel
Updated Tools:
- Time: Retained from Version 1.
- Corrective_RAG: A new tool that routes queries through three channels:
- Retrieval: Fetches relevant information.
- SQL: Queries structured data.
- Websearch: Performs web searches for external data.
The Corrective_RAG tool optimizes query routing for more efficient and accurate responses.
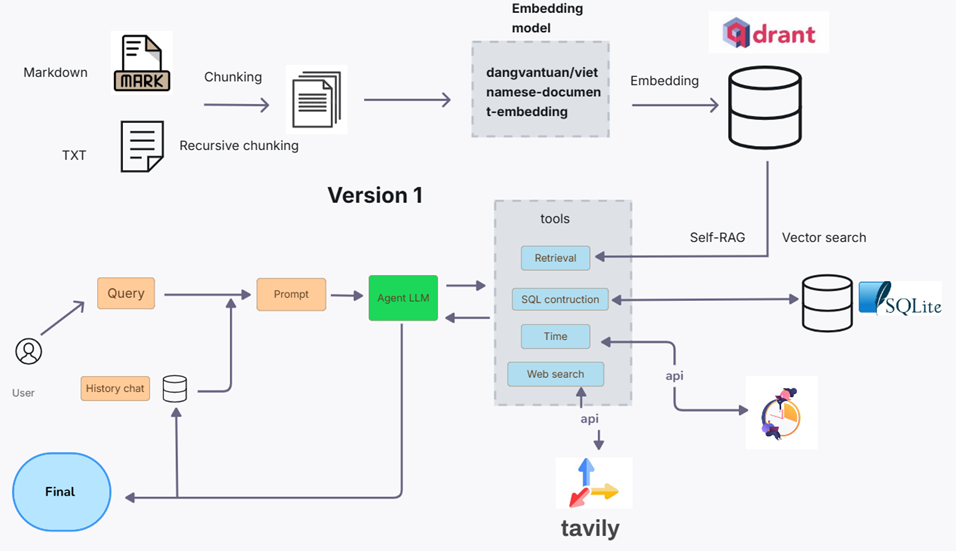
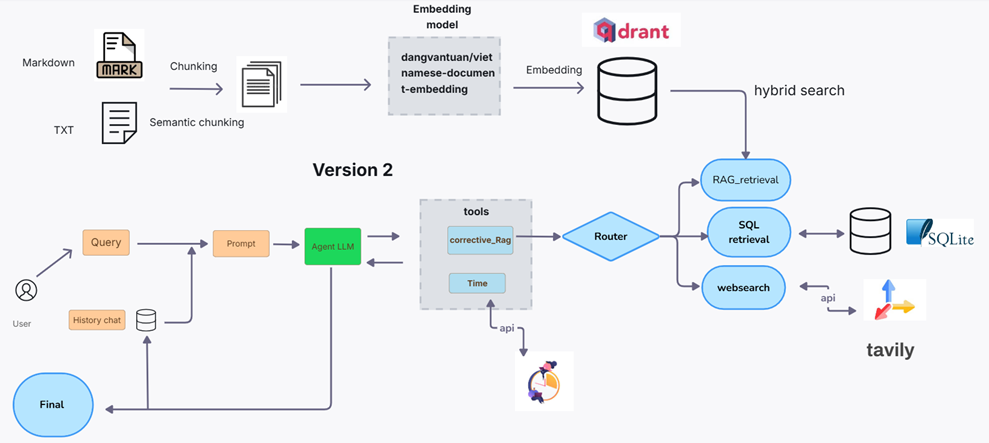
Table of content
- Guiding assistant for Vietnamese university admissions powered by Advanced RAG
- Link
- Architecture System
- Version 1
- Version 2 (Final Version) - Table of content
- Project structure
- Getting started
- Evaluate
- DEMO
- References
- Contact
Project structure
├── UNIVERSITY_ADMISSIONS_ASSISTANT
│ ├── src # Source code
│ │ ├── adaptive_rag.py # Adaptive retrieval-augmented generation
│ │ ├── corrective_rag.py # Corrective RAG implementation
│ │ ├── gemi_agent_v1.py # First version of GEMI agent
│ │ ├── gemi_agent_v2.py # Updated version of GEMI agent
│ │ ├── grader.py # Grading system logic
│ │ ├── load_key.py # API key loading utilities
│ │ ├── main.py # Main entry point for the application
│ │ ├── query_router.py # Routing queries to appropriate modules
│ │ ├── query_to_sql.py # Convert queries to SQL statements
│ │ ├── query_transformation.py # Transform query formats
│ │ ├── retrieval_hybrid.py # Hybrid retrieval techniques
│ │ ├── retrieval_nv.py # Named-variant retrieval implementation
│ │ ├── serve.py # Server-related functionalities
│ │ ├── university_admissions.db # Database for university admissions
│ │ ├── web_search.py # Web-based search utilities
│ ├── README.md # Project documentation
│ ├── requirements.txt # Dependencies for the project
│ ├── .env # Environment variables (API keys, etc.)
│ ├── .env.example # Example of environment configuration
│ ├── .gitignore # Ignore files for Git
│ ├── creadientials_vertex.json # JSON config file (possibly credentials)
Getting started
To get starte with this project, we need to do the following
Config all api key in .env.example(Qdrant, Tavily, GROQ, GEMINAI, LANGCHAIN SMITH)
Note:
The reason for using two Qdrant APIs is that one is used for storing the database with recursive chunking, while the other is used for semantic chunking.
Additionally, during development, you can experiment with the free $300 Google Cloud Console credits to obtain API keys.
- While configuring, I also use LLM ChatVertexAI, and the setup involves configuring Google Console and downloading the JSON file. This file is required to load the LLM values for the agent.
You can refer to the following link for a guide on setup and credential creation:
LangChain Google Vertex AI Setup
Or you can see step by step to get file creadiential json in this below:
Step 1: Create a Google Cloud Project
- Go to Google Cloud Console.
- Click on "Select a project" (or "Create Project" if you don’t have one).
- Enter a Project Name and click "Create".
Step 2: Enable Vertex AI API
- In the Google Cloud Console, navigate to APIs & Services → Library.
- Search for "Vertex AI API".
- Click Enable.
Step 3: Create a Service Account
- Go to APIs & Services → Credentials.
- Click "Create Credentials" → "Service account".
- Enter a Name, ID, and Description, then click Create.
- Assign the Vertex AI User and Editor roles (or a custom role with sufficient permissions).
- Click Done.
Step 4: Generate and Download the JSON Key
- In the Credentials section, find the newly created Service Account.
- Click on it → Navigate to the Keys tab.
- Click "Add Key" → "Create new key".
- Select "JSON" format and click "Create".
- A JSON file will be downloaded to your system (e.g., tdtuchat-16614553b756.json).
Step 5:
- Rename file json in 2 files python gemi_agent_v1.py, gemi_agent_v2.py correctively
Run local
Prepare enviroment
Install all dependencies dedicated to the project in local
python -m venv .venv
source .venv/Scripts/activate
pip install -r requirements.txt
After configuring all JSON files, setting up all API keys in the .env file, and installing dependencies from requirements.txt, follow these steps to run the system:
-
Open Terminal
-
Activate Virtual Environment
- Using venv:
source .venv\Scripts\activate # On Windows
- Using venv:
-
Navigate to the Project Folder
cd UNI_ADMISSIONS_ASSISTANT/src -
Run the Application
streamlit run main.py
This will start the University Admission Assistant system, which will be accessible in your browser via the Streamlit interface. 🚀
Evaluate
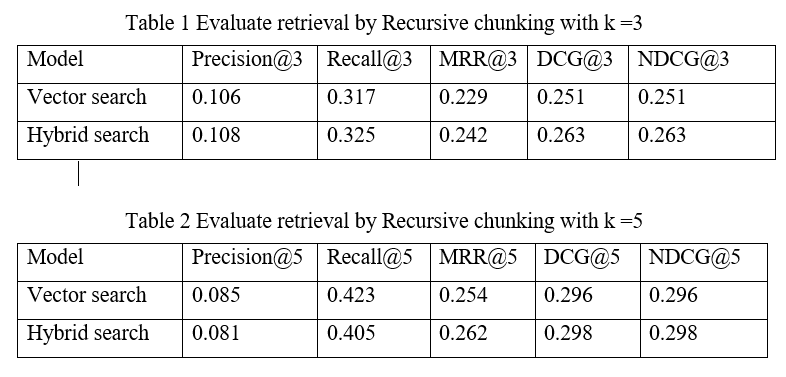
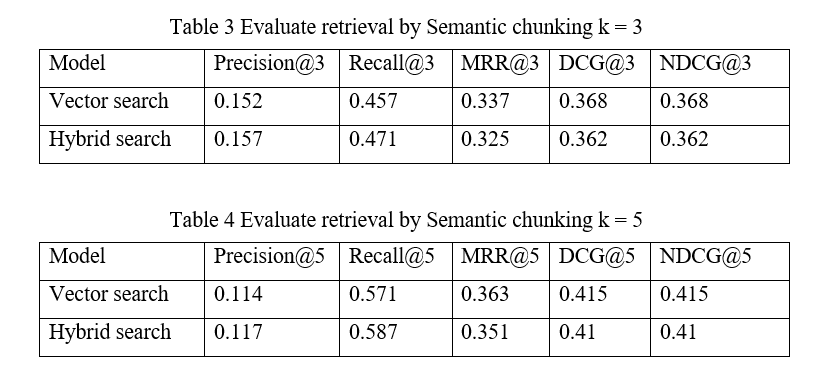
In this experiment, we compare the performance of two information retrieval methods, Navie RAG and Hybrid Search, when using the chunking methodology with recursive splitting. The two models are evaluated on prominent assessment measures such as Precision@k (P@k), Recall@k, Mean Reciprocal Rank (MRR@k), Discounted Cumulative Gain (DCG@k), and Normalized DCG (NDCG@k), with k = 3 and k = 5, respectively.
Watch : Data evaluation
Recursive chunking
Semantic chunking
Evaluation Using RAGAS
To evaluate the system, we tested two versions: Self-RAG (Version 1) and Corrective-RAG (Version 2). LangChain Smith was also used to assess workflow performance and processing times.
| Metric | Self-RAG (Version 1) | Corrective-RAG (Version 2) |
|---|---|---|
| Faithfulness | 0.7241 | 0.834 |
| Answer Relevancy | 0.7161 | 0.666 |
| Context Recall | 0.3113 | 0.504 |
| Context Precision | 0.4167 | 0.571 |
| Semantic Similarity | 0.8835 | 0.886 |
| Answer Correctness | 0.4014 | 0.565 |
Performance Analysis
- Corrective-RAG (Version 2) shows improved faithfulness, context recall, and answer correctness.
- Self-RAG (Version 1) performs slightly better in answer relevancy but struggles with context recall and correctness.
Processing Time Comparison
- Self-RAG: Execution times range from 5.64 to 11.84 seconds, with extreme cases reaching 88+ seconds, showing high inconsistency.
- Corrective-RAG: Execution times vary from 7.66 to 55.31 seconds, with some stable runs under 10 seconds and complex queries extending beyond 20 seconds.
Optimization Considerations
- Self-RAG struggles with complex queries, requiring query optimization and system enhancements for stability.
- Corrective-RAG still experiences variability, which could be improved through caching and processing pipeline optimizations.
In conclusion, Corrective-RAG (Version 2) provides better faithfulness, context handling, and correctness, making it a more reliable choice despite some runtime fluctuations.
DEMO
Version 1
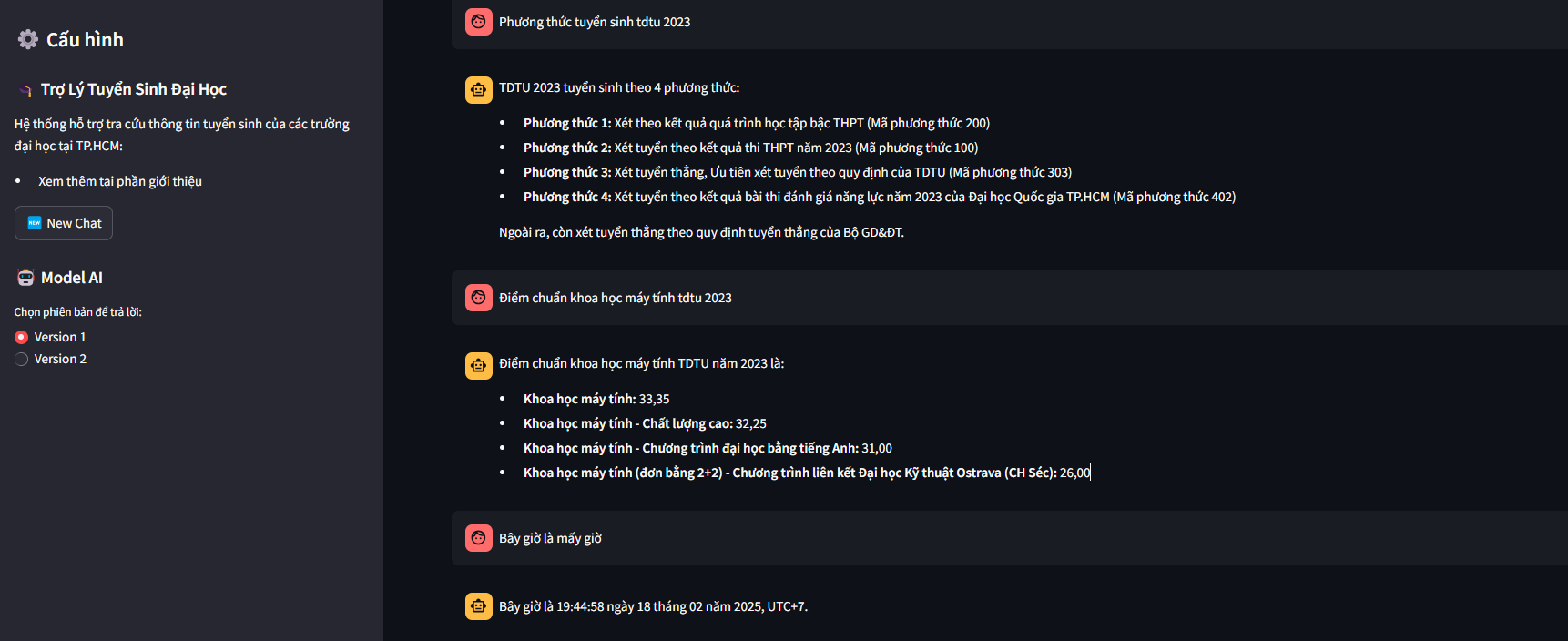
Version 2
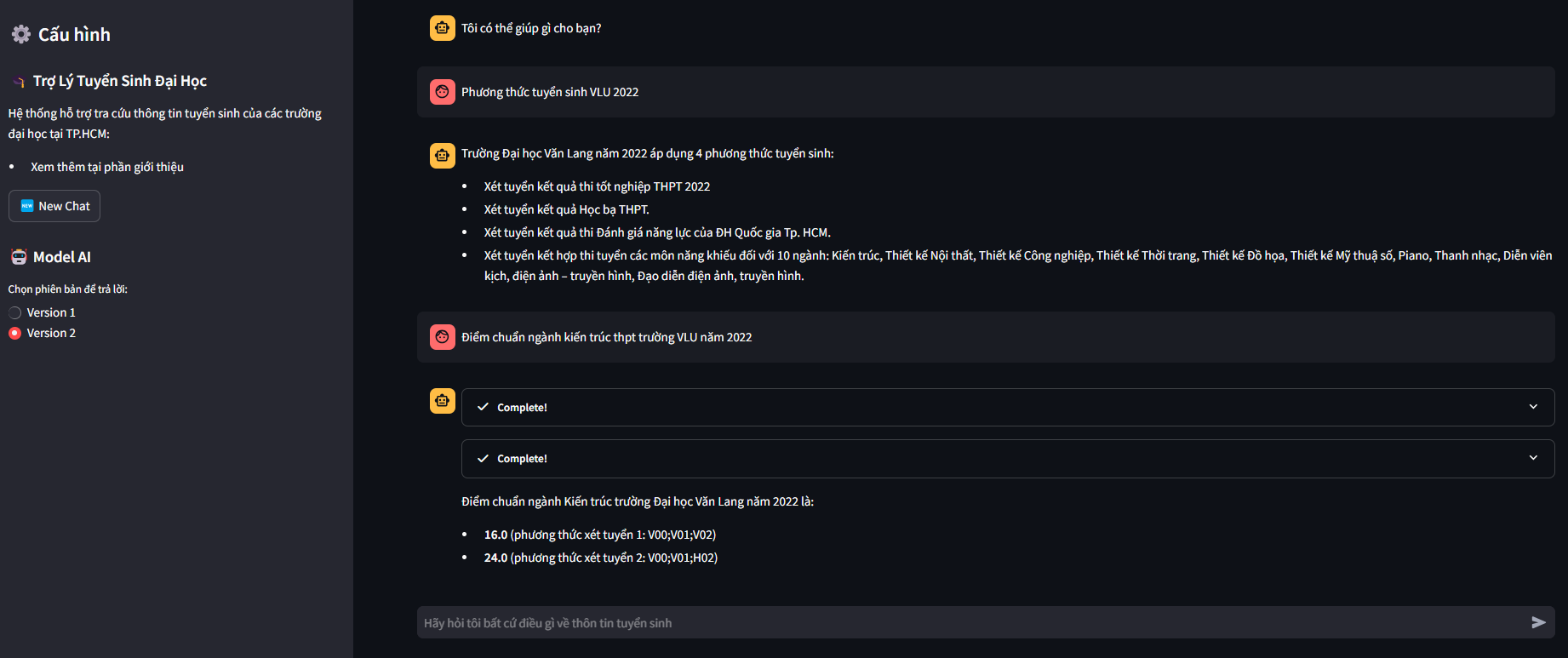
References
Paper
[1] Wang, H., Zhang, R., Tao, M., & Liu, Y. (2023). Retriever-Augmented Generation for Knowledge-Intensive NLP Tasks: A Survey. arXiv. https://arxiv.org/pdf/2307.06435
[2] Ram, O., Shreter, U., Shoham, N., & Levy, O. (2023). Corrective RAG: Intervention-Based Retrieval for Mitigating Hallucination in LLMs. arXiv. https://arxiv.org/pdf/2303.18223
[3] Yan, S.-Q., Gu, J.-C., Zhu, Y., & Ling, Z.-H. (2024). Corrective Retrieval Augmented Generation. arXiv. https://arxiv.org/abs/2401.15884
[4] Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y., Fu, F., Yang, L., Zhang, W., Jiang, J., & Cui, B. (2024). Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv. https://arxiv.org/abs/2402.19473
[5] Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., & Wang, H. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv. https://arxiv.org/abs/2312.10997
[6] Ye, Q., Axmed, M., Pryzant, R., & Khani, F. (2023). Prompt Engineering a Prompt Engineer. arXiv. https://arxiv.org/abs/2311.05661
[7] Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv. https://arxiv.org/abs/2309.15217
[8] Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). SELF-RAG: Learning to retrieve, generate, and critique through self-reflection [Preprint]. arXiv. https://arxiv.org/abs/2310.11511
Others
Contact
If you want to support or get API and URL QDRANT ask us:
- Member 1
- Hoang Dinh Quy Vu
- 0868245465
- hoangdinhquyvu.snape.22@gmail.com
- Memeber 2:
- Tran Quoc An
- 0383474552
- quocan1203it@gmail.com