Fine tune
1. Giới thiệu
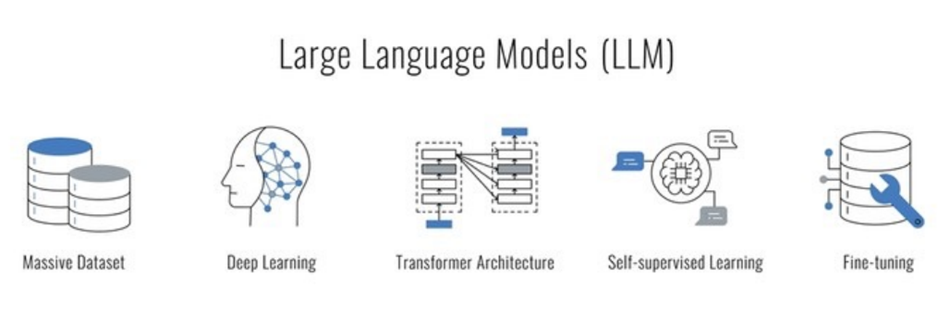
LLM là viết tắt của Large Language Model (Mô hình Ngôn ngữ Lớn). Đây là một loại mô hình học sâu được huấn luyện trên một lượng lớn dữ liệu văn bản để hiểu và sinh ra ngôn ngữ tự nhiên. Các LLM có khả năng xử lý và tạo ra văn bản, thực hiện các nhiệm vụ như trả lời câu hỏi, dịch ngôn ngữ, tóm tắt văn bản, và nhiều ứng dụng khác.

LLM là sự kết hợp của nhiều yếu tố quan trọng, bao gồm:
- Lượng dữ liệu lớn: Cung cấp cho mô hình nền tảng kiến thức rộng lớn.
- Học sâu: Cho phép mô hình học các mối quan hệ phức tạp giữa các từ.
- Kiến trúc Transformer: Nâng cao khả năng hiểu ngữ cảnh và tạo ra văn bản chất lượng.
- Học tự giám sát: Giúp mô hình học hỏi từ dữ liệu không có nhãn.
- Điều chỉnh tinh: Cho phép mô hình thực hiện các nhiệm vụ cụ thể.
2. Tại sao phải fine tuning
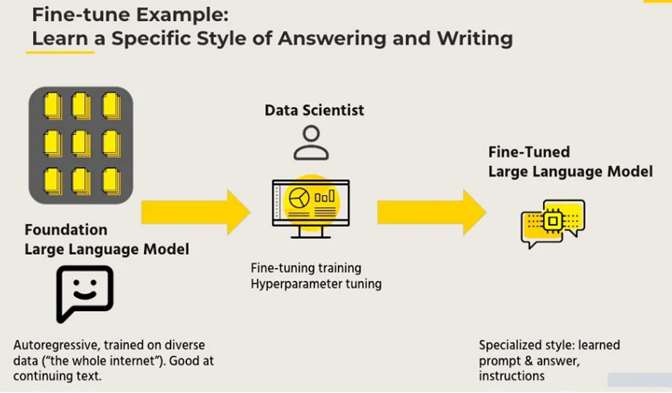
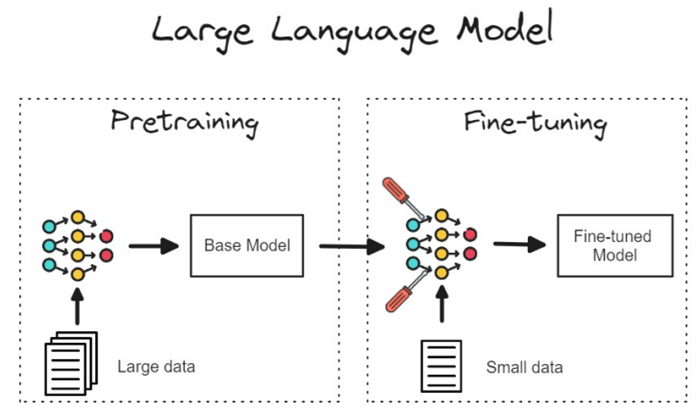
Fine-tuning là quá trình tinh chỉnh một mô hình đã được huấn luyện trước (pre-trained model) để nó hoạt động tốt hơn trên một nhiệm vụ cụ thể hoặc một tập dữ liệu cụ thể. Dưới đây là một số lý do quan trọng tại sao việc fine-tuning là cần thiết:
-
Tinh Chỉnh Mô Hình Để Phù Hợp Với Nhiệm Vụ Cụ Thể
- Tối ưu hóa cho nhiệm vụ cụ thể: Mô hình đã được huấn luyện trước (pre-trained model) như GPT-3 hoặc BERT thường được huấn luyện trên một tập dữ liệu rộng lớn và tổng quát. Fine-tuning giúp điều chỉnh mô hình để cải thiện hiệu suất cho các nhiệm vụ cụ thể như phân loại văn bản, nhận dạng thực thể, hoặc dịch ngôn ngữ.
- Tăng cường độ chính xác: Mặc dù mô hình pre-trained có thể tạo ra các dự đoán chính xác ở mức độ cơ bản, fine-tuning giúp cải thiện độ chính xác và phù hợp với các đặc điểm của dữ liệu cụ thể.
-
Tiết Kiệm Thời Gian và Tài Nguyên
- Giảm thời gian huấn luyện: Huấn luyện một mô hình từ đầu yêu cầu rất nhiều dữ liệu và tài nguyên tính toán. Fine-tuning sử dụng một mô hình đã được huấn luyện trước, giúp tiết kiệm thời gian và tài nguyên.
- Tận dụng kiến thức đã có: Các mô hình pre-trained đã học được rất nhiều thông tin từ dữ liệu huấn luyện rộng lớn. Fine-tuning cho phép tận dụng kiến thức này để áp dụng cho nhiệm vụ cụ thể mà không cần phải huấn luyện từ đầu.
-
Cải Thiện Hiệu Suất Trong Các Tình Huống Cụ Thể
- Phù hợp với dữ liệu đặc thù: Dữ liệu huấn luyện cụ thể cho nhiệm vụ hoặc miền của bạn có thể khác biệt so với dữ liệu tổng quát. Fine-tuning giúp mô hình thích nghi với các đặc điểm và mẫu trong dữ liệu cụ thể của bạn.
- Điều chỉnh cho các biến thể ngữ nghĩa: Trong các nhiệm vụ như sinh văn bản hoặc dịch máy, fine-tuning giúp mô hình tạo ra văn bản hoặc dịch chính xác hơn theo ngữ cảnh cụ thể.
-
Xử Lý Các Tình Huống Đặc Biệt
- Giải quyết bias trong dữ liệu: Mô hình pre-trained có thể có các bias từ dữ liệu huấn luyện rộng lớn. Fine-tuning có thể giúp điều chỉnh hoặc giảm thiểu các bias này, đặc biệt khi dữ liệu của bạn có các đặc điểm văn hóa, ngữ nghĩa hoặc ngữ cảnh khác biệt.
- Tinh chỉnh để đáp ứng các yêu cầu cụ thể: Fine-tuning có thể điều chỉnh mô hình để đáp ứng các yêu cầu cụ thể của ứng dụng, như hạn chế đầu ra, thêm yêu cầu ngữ pháp hoặc tuân thủ các quy định cụ thể.
-
Tối Ưu Hóa Cho Hiệu Suất
- Tinh chỉnh hyperparameters: Trong quá trình fine-tuning, bạn có thể điều chỉnh các hyperparameters như learning rate, batch size, hoặc số lượng epoch để tối ưu hóa hiệu suất của mô hình cho nhiệm vụ cụ thể

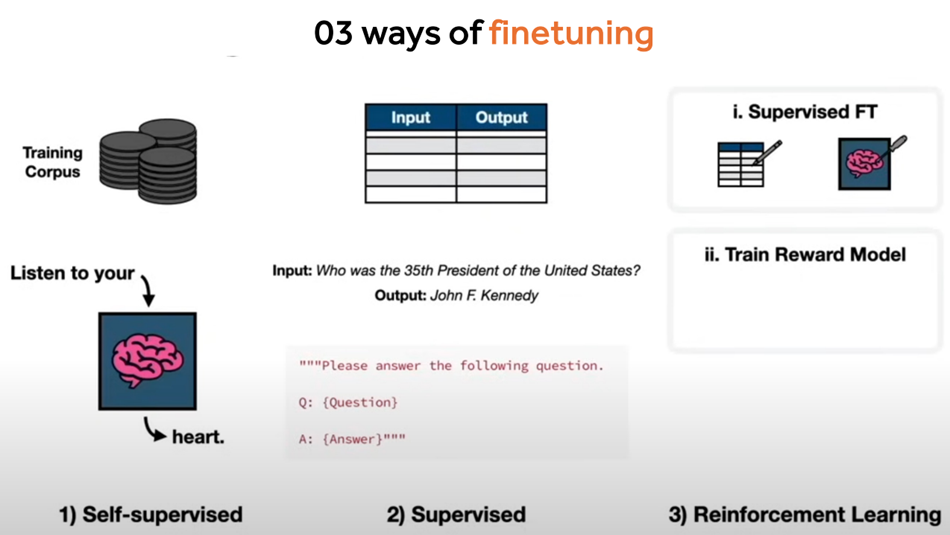
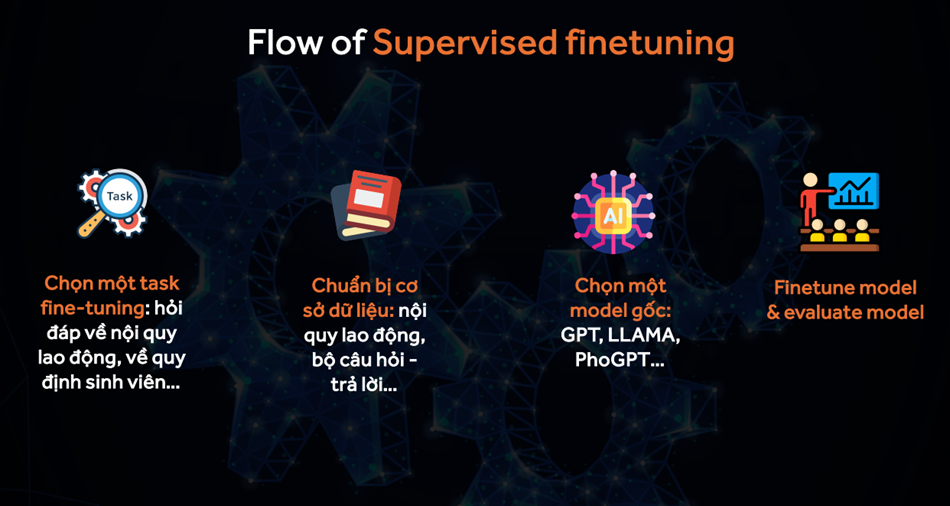
3. Cách để fine tuning
Self-Supervised Learning (Học Tự Giám Sát):
- Cách làm: Sử dụng dữ liệu không có nhãn để tạo nhiệm vụ phụ (như dự đoán từ bị ẩn) và fine-tune mô hình dựa trên các nhiệm vụ này.
- Mục tiêu: Học các đặc điểm và mối quan hệ trong dữ liệu mà không cần gán nhãn trực tiếp.
Supervised Learning (Học Có Giám Sát):
- Cách làm: Fine-tune mô hình trên dữ liệu có nhãn để cải thiện hiệu suất cho các nhiệm vụ cụ thể như phân loại văn bản hoặc nhận dạng thực thể.
- Mục tiêu: Tinh chỉnh mô hình để tối ưu hóa độ chính xác cho nhiệm vụ cụ thể dựa trên các nhãn có sẵn.
Reinforcement Learning (Học Tăng Cường):
- Cách làm: Fine-tune mô hình bằng cách học từ phần thưởng hoặc hình phạt từ môi trường khi thực hiện các hành động.
- Mục tiêu: Tối ưu hóa chính sách của mô hình để đạt được phần thưởng tối đa trong một nhiệm vụ cụ thể.
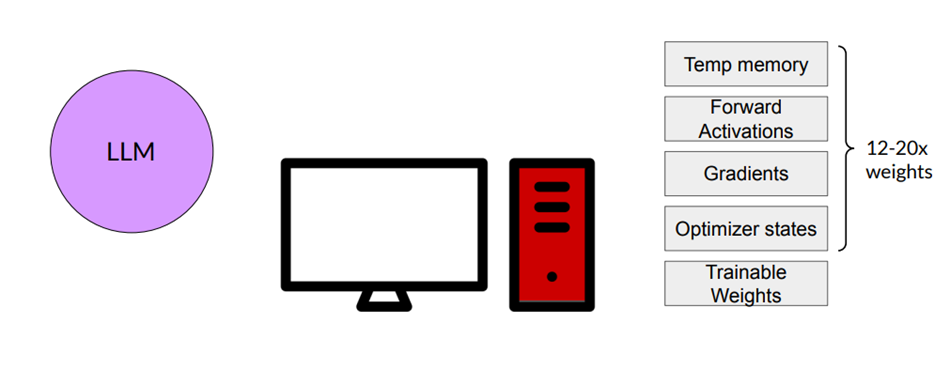
4. Thách thức khi train LLM
- Yêu cầu về tài nguyên tính toán khổng lồ:
- Bộ nhớ tạm (Temp memory): Để xử lý lượng thông tin khổng lồ trong quá trình huấn luyện, LLM cần một lượng bộ nhớ tạm rất lớn.
- Tính toán tiền xuôi (Forward Activations): Các phép tính tiền xuôi để cập nhật trọng số của mô hình cũng tiêu tốn rất nhiều tài nguyên tính toán.
- Gradient: Quá trình tính toán gradient để cập nhật trọng số đòi hỏi nhiều phép toán phức tạp.
- Optimizer states: Các trạng thái của bộ tối ưu hóa cũng chiếm một lượng bộ nhớ đáng kể.
- Trọng số có thể huấn luyện (Trainable Weights): LLM có hàng tỷ tham số cần được huấn luyện, đòi hỏi dung lượng lưu trữ lớn.
- Thách thức: Việc quản lý và sử dụng hiệu quả các tài nguyên tính toán này là một trong những bài toán khó nhất trong việc huấn luyện LLM.
2. Dữ liệu huấn luyện: - Lượng dữ liệu khổng lồ: LLM cần được huấn luyện trên một lượng dữ liệu văn bản khổng lồ để có thể hiểu và tạo ra văn bản chất lượng cao.
- Chất lượng dữ liệu: Không phải tất cả dữ liệu đều có chất lượng tốt. Dữ liệu nhiễu, sai lệch hoặc thiên vị có thể ảnh hưởng đến chất lượng của mô hình.
- Tiền xử lý dữ liệu: Quá trình làm sạch, chuẩn hóa và phân loại dữ liệu là một công việc tốn thời gian và đòi hỏi nhiều kỹ năng.
- Thách thức: Thu thập, làm sạch và chuẩn bị dữ liệu chất lượng cao cho việc huấn luyện LLM là một thách thức lớn.
3. Thời gian huấn luyện: - Thời gian dài: Việc huấn luyện một LLM có thể mất nhiều ngày, thậm chí nhiều tuần.
- Chi phí: Chi phí điện năng và tài nguyên tính toán cho quá trình huấn luyện là rất cao.
- Thách thức: Làm thế nào để rút ngắn thời gian huấn luyện mà không làm giảm chất lượng của mô hình là một vấn đề cần được nghiên cứu.
4. Kiến trúc mô hình: - Độ phức tạp: Kiến trúc của LLM rất phức tạp, bao gồm nhiều lớp và hàng tỷ tham số.
- Tối ưu hóa siêu tham số: Việc tìm ra các siêu tham số tối ưu cho mô hình là một quá trình thử và sai tốn thời gian.
- Thách thức: Thiết kế và tối ưu hóa kiến trúc của LLM là một bài toán khó đòi hỏi kiến thức chuyên sâu về học sâu.
5. Đánh giá mô hình: - Tiêu chí đánh giá đa dạng: Việc đánh giá chất lượng của một LLM đòi hỏi nhiều tiêu chí khác nhau, bao gồm độ chính xác, sự mạch lạc, tính sáng tạo, v.v.
- Khó khăn trong việc so sánh: Việc so sánh giữa các LLM khác nhau là rất khó khăn do không có một tiêu chuẩn đánh giá chung.
5. PEFT
PEFT (Parameter-Efficient Fine-Tuning) là một phương pháp fine-tuning mô hình học sâu nhằm cải thiện hiệu quả của việc điều chỉnh mô hình mà không cần phải thay đổi toàn bộ các tham số của nó. PEFT tập trung vào việc tối ưu hóa một phần nhỏ của mô hình, thường là các tham số hoặc lớp cụ thể, thay vì toàn bộ mô hình.
Lợi Ích của PEFT
1. Tiết Kiệm Tài Nguyên:
- Giảm Khối Lượng Tính Toán: PEFT yêu cầu ít tài nguyên tính toán hơn so với việc fine-tuning toàn bộ mô hình, vì nó chỉ tối ưu hóa một phần nhỏ của mô hình.
- Tiết Kiệm Bộ Nhớ: Chỉ cần lưu trữ và cập nhật các tham số được tinh chỉnh, giúp tiết kiệm bộ nhớ so với việc lưu trữ và cập nhật toàn bộ mô hình.
2. Nhanh Hơn và Hiệu Quả Hơn:
- Thời Gian Huấn Luyện: Việc fine-tuning chỉ các tham số hoặc lớp cụ thể giúp giảm thời gian huấn luyện.
- Quản Lý Dễ Dàng: Quá trình huấn luyện và điều chỉnh dễ dàng hơn khi chỉ cần làm việc với một phần nhỏ của mô hình.
3. Dễ Dàng Điều Chỉnh:
- Tinh Chỉnh Cho Nhiệm Vụ Cụ Thể: PEFT cho phép bạn dễ dàng điều chỉnh mô hình cho các nhiệm vụ hoặc miền cụ thể mà không cần thay đổi toàn bộ cấu trúc của mô hình.
- Học Tốt Hơn Từ Dữ Liệu Đặc Thù: Mô hình có thể học tốt hơn từ dữ liệu đặc thù của nhiệm vụ cụ thể khi chỉ fine-tuning phần liên quan.
4. Giảm Thiểu Overfitting:
- Giảm Rủi Ro Overfitting: Tinh chỉnh một phần nhỏ của mô hình có thể giúp giảm nguy cơ overfitting so với việc huấn luyện toàn bộ mô hình từ đầu, vì mô hình ít có khả năng học các đặc điểm không mong muốn từ dữ liệu.
5. Khả Năng Tái Sử Dụng Mô Hình:
- Tái Sử Dụng Hiệu Quả: Các mô hình pre-trained có thể được fine-tune cho nhiều nhiệm vụ khác nhau mà không cần phải huấn luyện lại từ đầu, giúp tiết kiệm thời gian và công sức
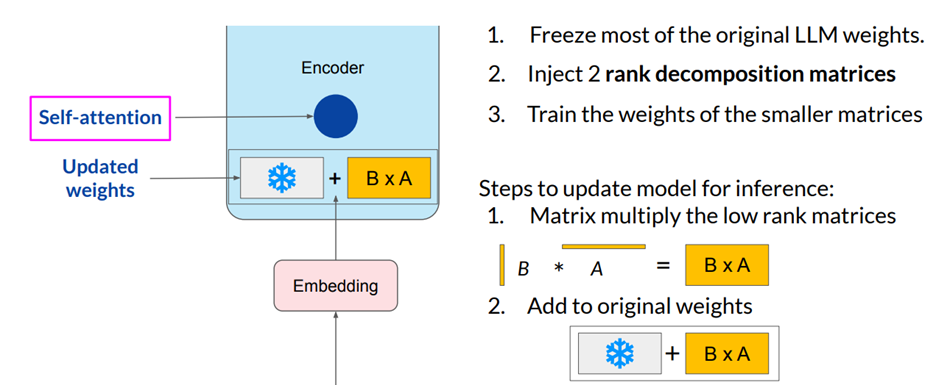
5.1 LoRA
- LoRA (Low-Rank Adaptation) là một kỹ thuật trong lĩnh vực fine-tuning mô hình học sâu, nhằm cải thiện hiệu quả fine-tuning của các mô hình lớn mà không cần phải tinh chỉnh toàn bộ các tham số của mô hình.
Cơ Bản về LoRA:
1. Ý Tưởng Chính:
- LoRA giảm số lượng tham số cần được fine-tune bằng cách thay thế một số ma trận trọng số của mô hình bằng các ma trận thấp hơn với hạng thấp. Điều này cho phép mô hình học được các điều chỉnh cần thiết mà không c
- Cần cập nhật tất cả các tham số của mô hình gốc.
2. Cách Hoạt Động:
- Ma Trận Thấp Hạng: Trong mô hình gốc, các ma trận trọng số lớn (như ma trận trong các lớp fully connected hoặc attention) được thay thế bằng các ma trận hạng thấp, thường là ma trận nhân với ma trận trọng số gốc.
- Bộ Điều Hợp (Adapters): LoRA sử dụng các bộ điều hợp nhỏ, là các mô-đun thêm vào các lớp của mô hình, giúp điều chỉnh các tham số cụ thể mà không cần phải thay đổi toàn bộ mô hình
5.2 Ví dụ
Sử dụng mô hình Transformer cơ sở do Vaswani và cộng sự trình bày năm 2017:
- Trọng số Transformer có kích thước d x k = 512 x 64
- Vậy 512 x 64 = 32.768 tham số có thể đào tạo
Trong LoRA với hạng r = 8:
- A có kích thước r x k = 8 x 64 = 512 tham số
- B có kích thước d x r = 512 x 8 = 4.096 tham số có thể đào tạo
- Giảm 86% tham số để đào tạo!
5.3 Chọn Lora rank
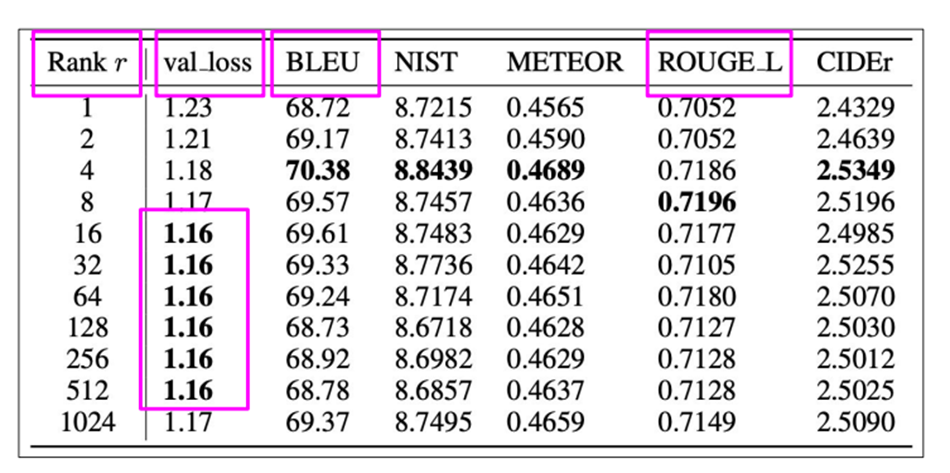
Hiệu quả của thứ hạng cao hơn dường như đạt đến mức ổn định: Việc sử dụng thứ hạng cao trong LoRA thường cho thấy sự cải thiện hiệu suất rõ rệt, nhưng hiệu quả của nó dường như đạt đến mức ổn định sau một mức độ nhất định. Điều này có nghĩa là việc tiếp tục tăng thứ hạng có thể không mang lại nhiều cải thiện đáng kể về hiệu suất, và việc chọn một giá trị hạng phù hợp có thể tối ưu hóa cả hiệu suất và tài nguyên.
Mối quan hệ giữa thứ hạng và kích thước tập dữ liệu cần nhiều dữ liệu thực nghiệm hơn: Mối liên hệ giữa thứ hạng của LoRA và kích thước của tập dữ liệu cần được khám phá thêm thông qua thực nghiệm. Cần có nhiều nghiên cứu và thử nghiệm hơn để xác định cách mà kích thước tập dữ liệu ảnh hưởng đến hiệu quả của các mức hạng khác nhau, từ đó điều chỉnh thứ hạng để tối ưu hóa hiệu suất cho các kích thước tập dữ liệu khác nhau.
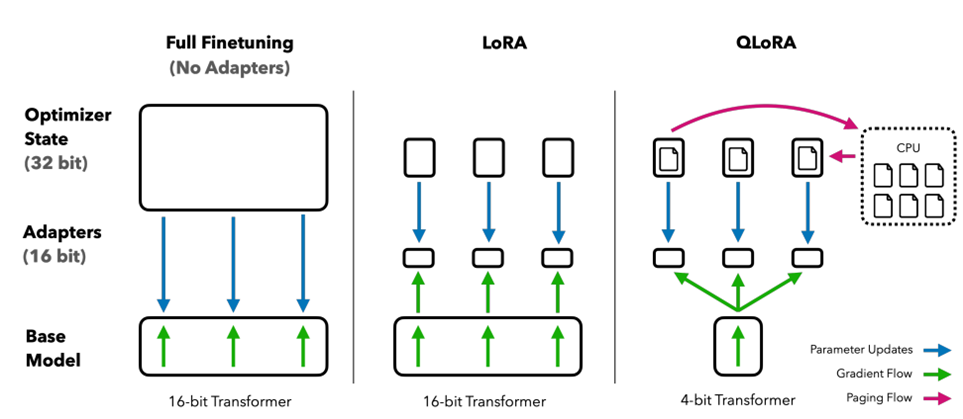
5.4 QLoRA
QLoRA (Quantized LoRA) là một phương pháp cải tiến của LoRA (Low-Rank Adaptation), với mục tiêu giảm bớt tài nguyên tính toán và bộ nhớ cần thiết trong việc fine-tuning các mô hình học sâu. Dưới đây là các điểm nổi bật của QLoRA:
Kiểu Dữ Liệu NormalFloat 4 bit (nf4):
- Mô Tả: QLoRA sử dụng kiểu dữ liệu NormalFloat 4 bit (nf4) để lượng tử hóa các tham số của mô hình. Điều này cho phép lưu trữ và tính toán với độ chính xác 4 bit, giúp giảm kích thước bộ nhớ cần thiết cho mô hình.
- Lợi Ích: Giảm kích thước bộ nhớ của các tham số mô hình mà không cần thay đổi quá nhiều cấu trúc của mô hình gốc.
Lượng Tử Hóa Kép:
- Mô Tả: Hỗ trợ lượng tử hóa kép, giảm bộ nhớ sử dụng thêm khoảng ~0,4 bit cho mỗi tham số. Đối với một mô hình lớn như mô hình 65B, điều này có thể giảm khoảng 3 GB bộ nhớ.
- Lợi Ích: Giảm bớt tài nguyên bộ nhớ cần thiết, giúp triển khai các mô hình lớn trên phần cứng có hạn chế bộ nhớ.
Quản Lý Bộ Nhớ GPU-CPU Thống Nhất:
- Mô Tả: QLoRA quản lý bộ nhớ giữa GPU và CPU một cách thống nhất, giúp giảm mức sử dụng bộ nhớ GPU.
- Lợi Ích: Cải thiện hiệu quả sử dụng tài nguyên phần cứng, giảm tải cho GPU và tăng khả năng xử lý các mô hình lớn.
Bộ Điều Hợp LoRA Ở Mọi Lớp:
- Mô Tả: Áp dụng bộ điều hợp LoRA không chỉ ở các lớp chú ý mà ở mọi lớp trong mô hình.
- Lợi Ích: Cung cấp khả năng điều chỉnh tinh tế cho các lớp khác nhau của mô hình, giúp cải thiện hiệu suất fine-tuning cho các nhiệm vụ cụ thể.
Giảm Độ Chính Xác:
- Mô Tả: Việc sử dụng kiểu dữ liệu 4 bit và lượng tử hóa có thể dẫn đến giảm độ chính xác so với các phương pháp fine-tuning truyền thống.
- Lợi Ích: Mặc dù độ chính xác có thể giảm, nhưng việc tiết kiệm tài nguyên và bộ nhớ có thể đáng giá cho nhiều ứng dụng, đặc biệt khi làm việc với các mô hình lớn hoặc trên phần cứng hạn chế
6. ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) là một bộ chỉ số được sử dụng để đánh giá chất lượng của các hệ thống sinh văn bản, đặc biệt trong các nhiệm vụ như tóm tắt văn bản, dịch máy và trả lời câu hỏi. ROUGE đo lường mức độ tương đồng giữa văn bản sinh ra bởi mô hình và văn bản tham chiếu (reference text) do con người tạo ra.
Các Thành Phần Chính của ROUGE
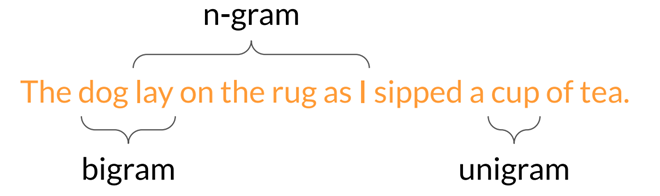
1. ROUGE-N:
- Mô Tả: Đo lường sự trùng khớp giữa các n-gram (chuỗi n từ liên tiếp) trong văn bản sinh ra và văn bản tham chiếu.
- Ví Dụ: ROUGE-1 tính toán độ chính xác và recall của các unigram (từ đơn), trong khi ROUGE-2 đo lường bigram (cặp từ liên tiếp).
2. ROUGE-L:
- Mô Tả: Đo lường sự trùng khớp của các chuỗi con dài nhất (longest common subsequence) giữa văn bản sinh ra và văn bản tham chiếu. Điều này giúp đánh giá cách mà các đoạn văn bản có thể được sinh ra hoặc tóm tắt một cách liên tục và mạch lạc.
- Lợi Ích: Hữu ích trong việc đo lường độ mạch lạc và tính liên kết của văn bản sinh ra.
3. ROUGE-Lsum:
- Mô Tả: Phiên bản mở rộng của ROUGE-L, đặc biệt được thiết kế để đánh giá chất lượng của các bản tóm tắt văn bản. Nó tính toán ROUGE-L cho toàn bộ văn bản tóm tắt, so với văn bản tham chiếu.
- Lợi Ích: Đánh giá hiệu quả của các mô hình tóm tắt trong việc giữ lại các thông tin quan trọng.
4.6.1 Ví dụ


7. Ví dụ
- Model sử dụng Vistral-7B-Chat

Tên đầy đủ: ViSTRAL (Vietnamese Structured Text Representations and Language)
*Kiến trúc:
- Decoder-only: Vistral-7B-Chat sử dụng kiến trúc decoder-only, tập trung vào việc sinh (generate) văn bản từ ngữ cảnh đã cho. Đây là kiến trúc phổ biến cho các mô hình sinh văn bản, cho phép mô hình tạo ra văn bản tự nhiên và mạch lạc.
Số tham số:
- 7 tỷ tham số: Mô hình này có kích thước 7 tỷ tham số, cho phép nó học và nắm bắt thông tin phong phú từ dữ liệu huấn luyện.
Ứng dụng:
- Chatbot và trợ lý ảo: Vistral-7B-Chat được thiết kế để hỗ trợ trong các ứng dụng chatbot và trợ lý ảo, cung cấp khả năng sinh văn bản tự nhiên và tương tác với người dùng.
- Hệ thống AI: Có thể được áp dụng trong các hệ thống AI yêu cầu khả năng sinh và hiểu văn bản, như hỗ trợ khách hàng, tạo nội dung, và nhiều hơn nữa.
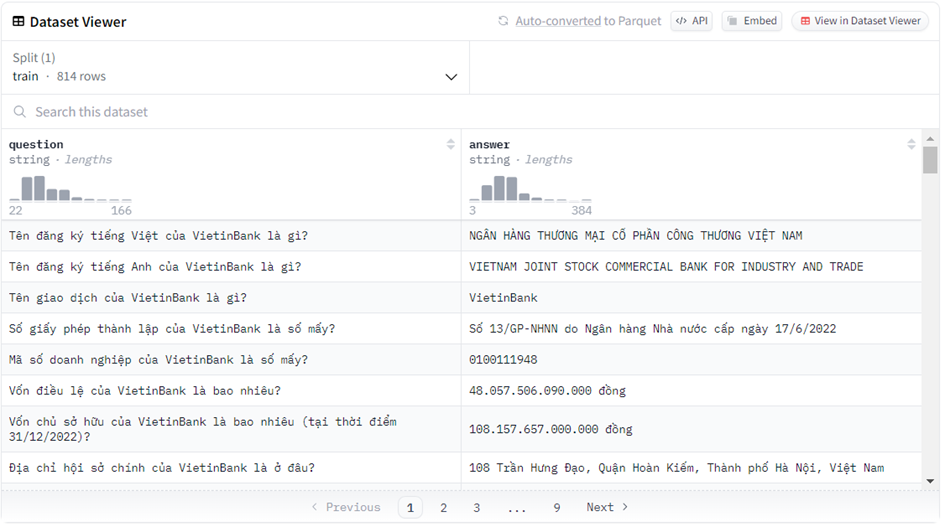
Về dataset:
Bên cạnh đó sử dụng WanDB để theo dõi quá trình train.

Và kết quả của quá trình train:
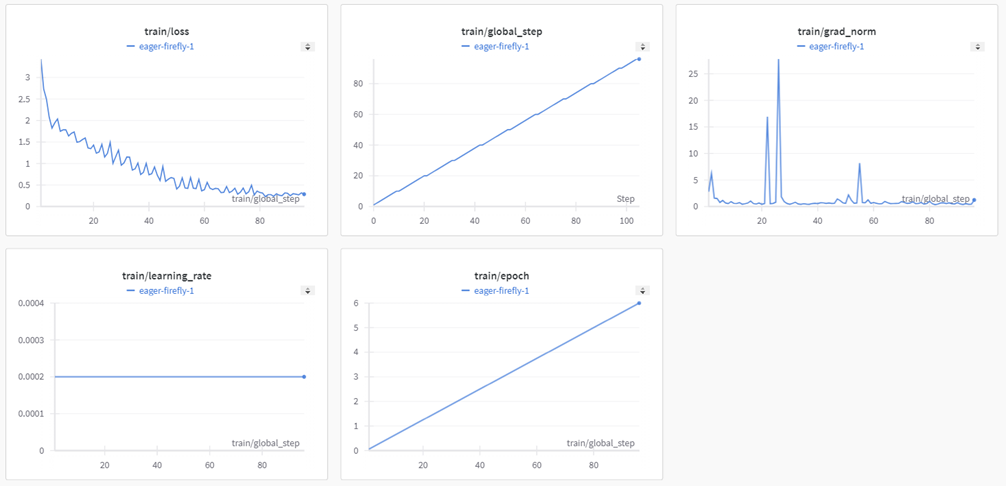
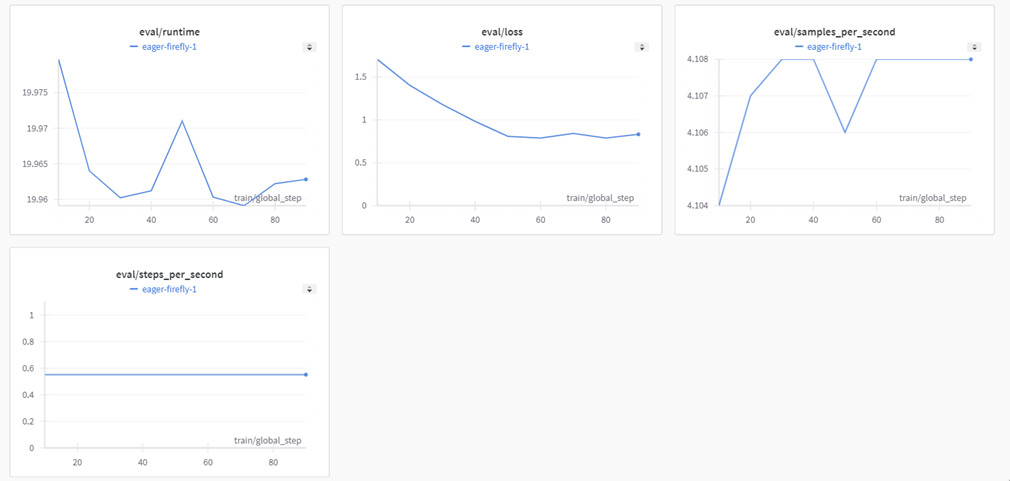
Và tóm tắt của wandb:
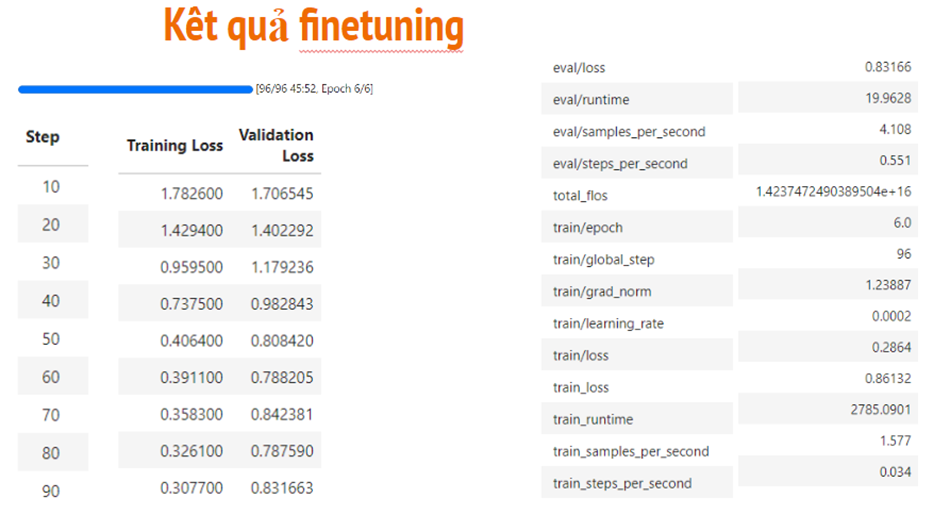
8. TÀI LIỆU THAM KHẢO
- [1706.03762] Attention Is All You Need. (2017, June 12). arXiv. https://arxiv.org/abs/1706.03762
- [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (2018, October 11). arXiv. Retrieved August 31, 2024, from https://arxiv.org/abs/1810.04805
- [1907.11692] RoBERTa: A Robustly Optimized BERT Pretraining Approach. (2019, July 26). arXiv. Retrieved August 31, 2024, from https://arxiv.org/abs/1907.11692
- ChatGPT Series 1: Bản chất ChatGPT hoạt động như thế nào? (n.d.). Viblo. Retrieved August 31, 2024, from Bản chất ChatGPT
- Nguyen, Q., & Nguyen, T. (2020, March 2). [2003.00744] PhoBERT: Pre-trained language models for Vietnamese. arXiv. Retrieved August 31, 2024, from https://arxiv.org/abs/2003.00744
- Ramponi's, M., & Ramponi, M. (2022, December 23). How ChatGPT actually works. AssemblyAI. Retrieved August 31, 2024, from https://www.assemblyai.com/blog/how-chatgpt-actually-works/
- RLHF và cách ChatGPT hoạt động. (n.d.). Viblo. Retrieved August 31, 2024, from https://viblo.asia/p/rlhf-va-cach-chatgpt-hoat-dong-3RlL5AEmLbB