MOE_V2
Note
-
Hiện tại đang có 3/3

-
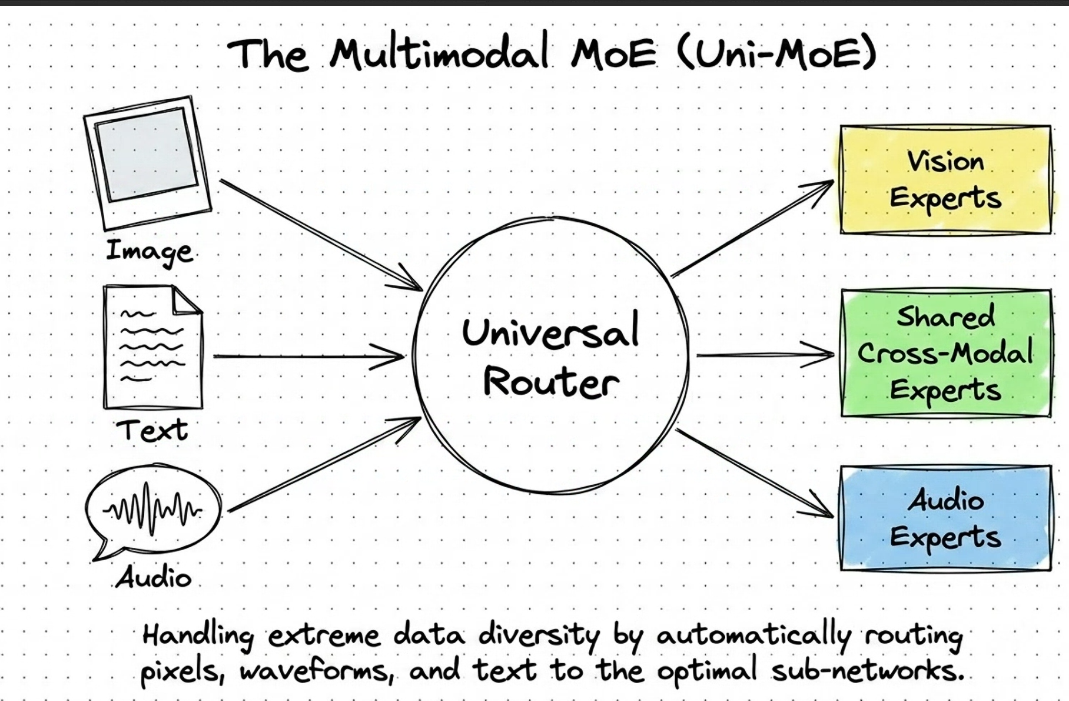
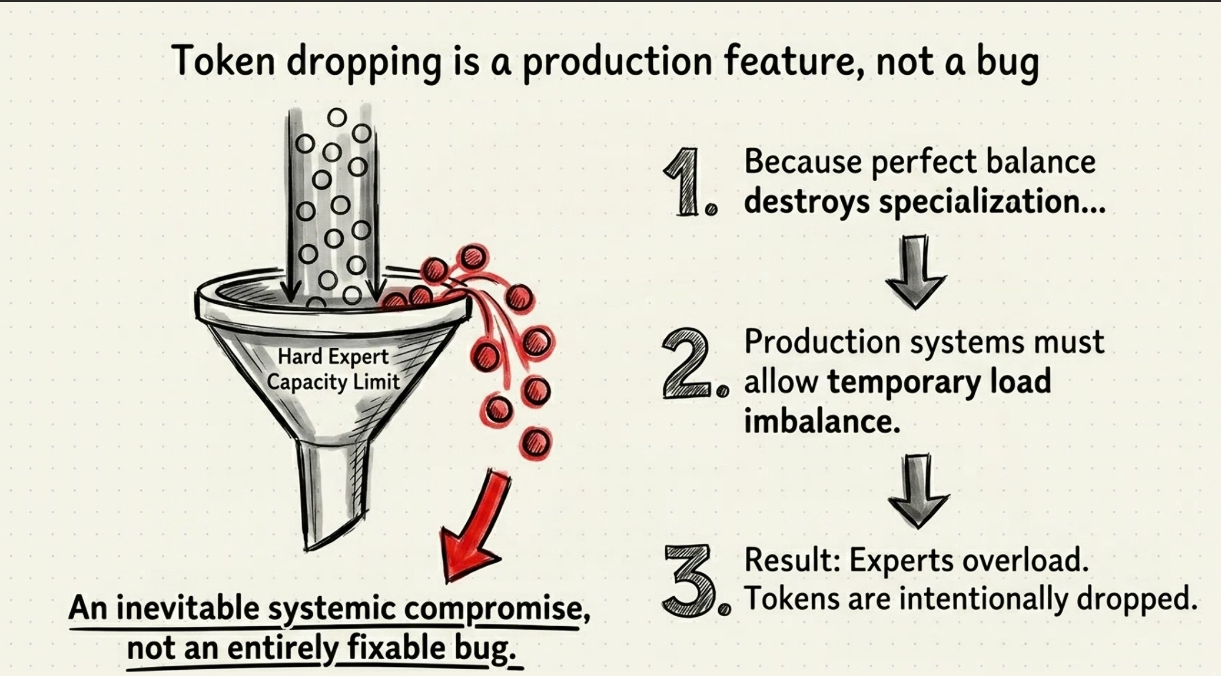
Moe is chuyên mô 2 tầng , neural và gate.
- H1 expert có tín hiệu mạnh - routing , tôi cần router đến expert này.
- nó không hiểu ngữ nghĩa và mà nó truyền đến tín hiệu mạnh nhất.
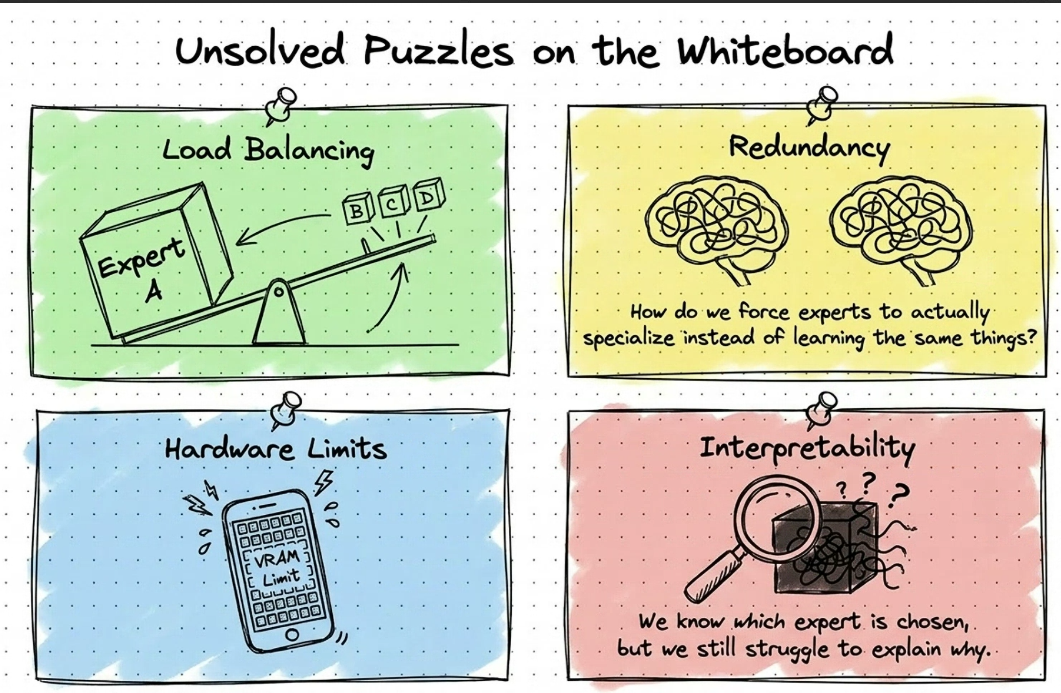
- H2 : 4/2026 : Làm sao phân vùng cái cụm các học này tốt hơn.
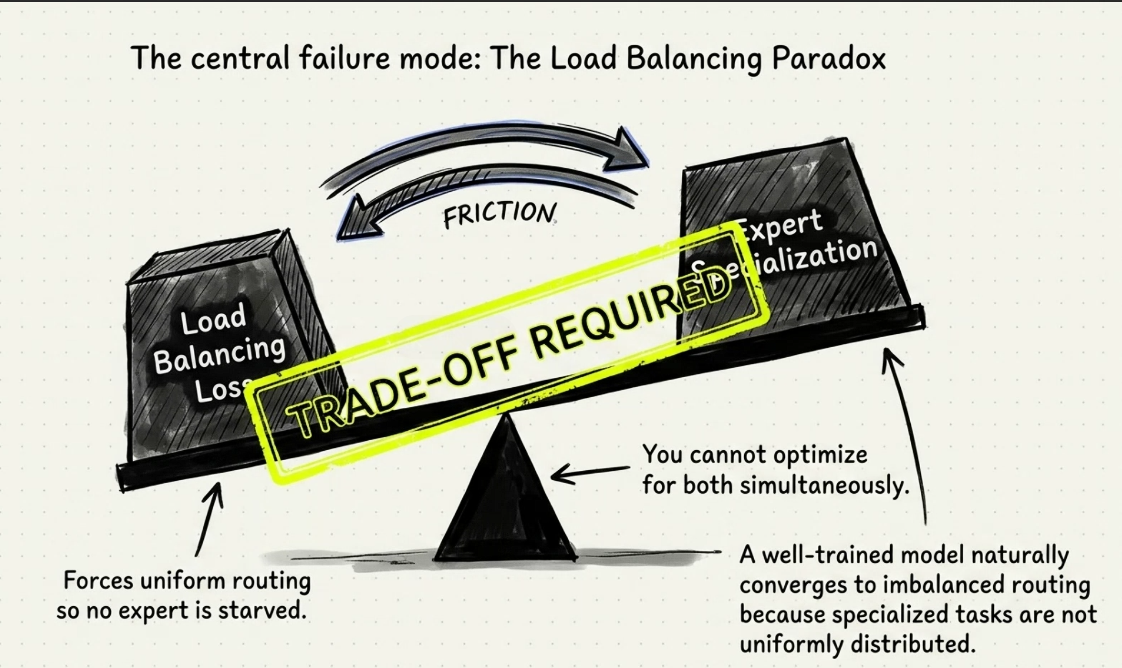
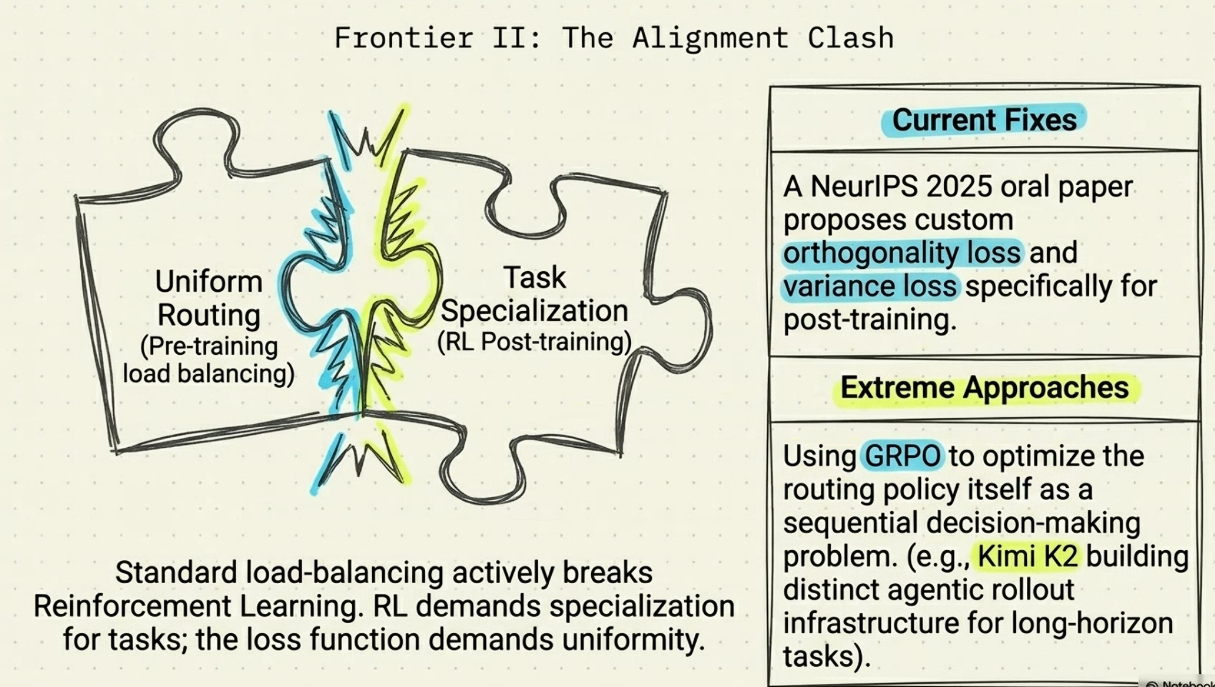
- H3: Routing load balance cần data distribution luôn không đều
- Được cân bằng hoàn hảo -> nếu expert sai thì khi những lĩnh vực noise hay outline(có thể phải chạm nhận data balance)
- H4: Token dropping - skip , move token qua expert khác nếu quá tải.
Scalling law
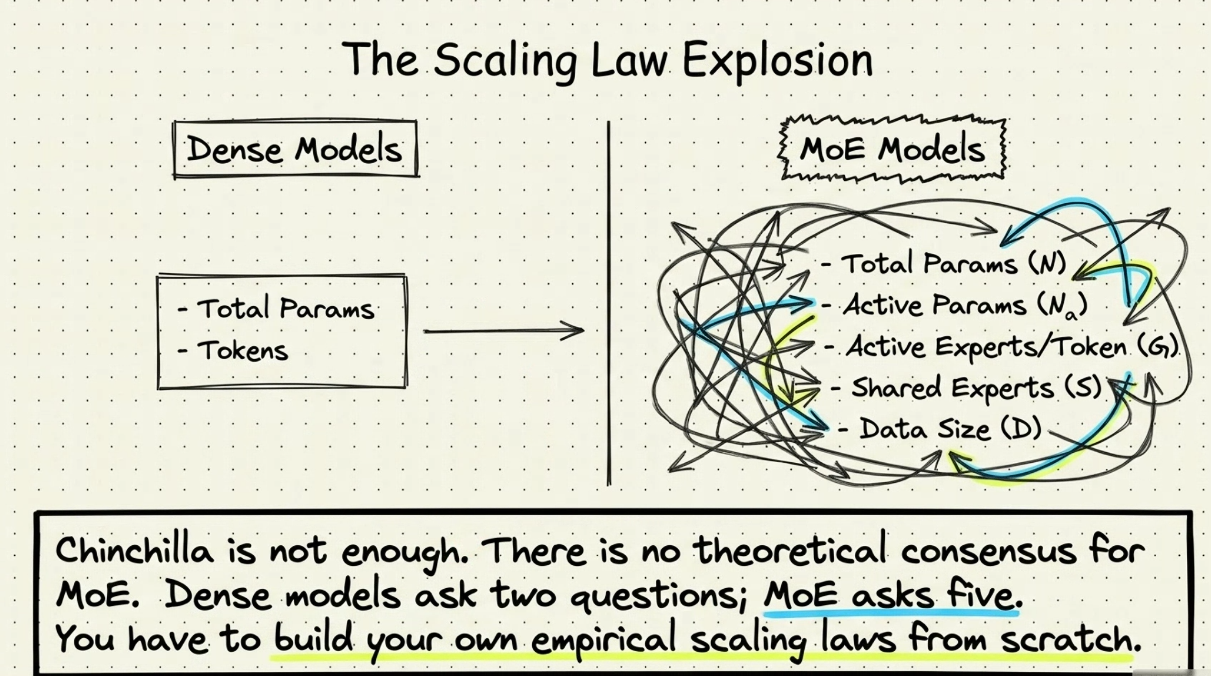
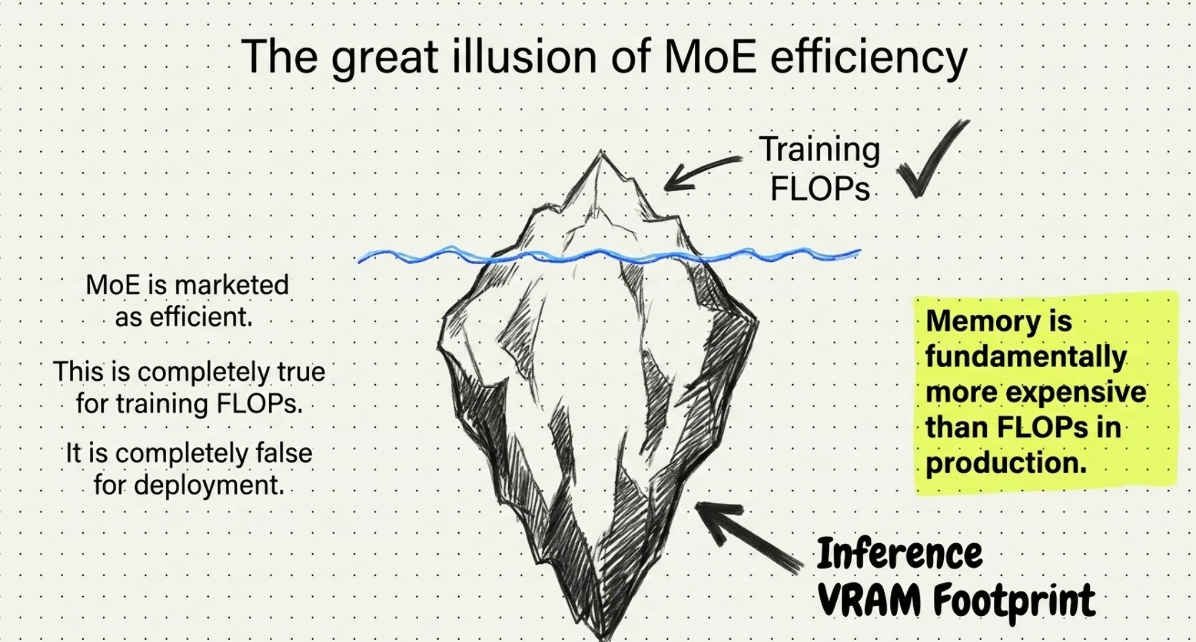
- Dense: Chinchilla
- Chạy labs - rule force tìm số expert cần token cho mỗi expert ? Cần tìm cho cái này.
- Đang tối ưu đang thử nghiệm để cho ra các para thử nghiệm
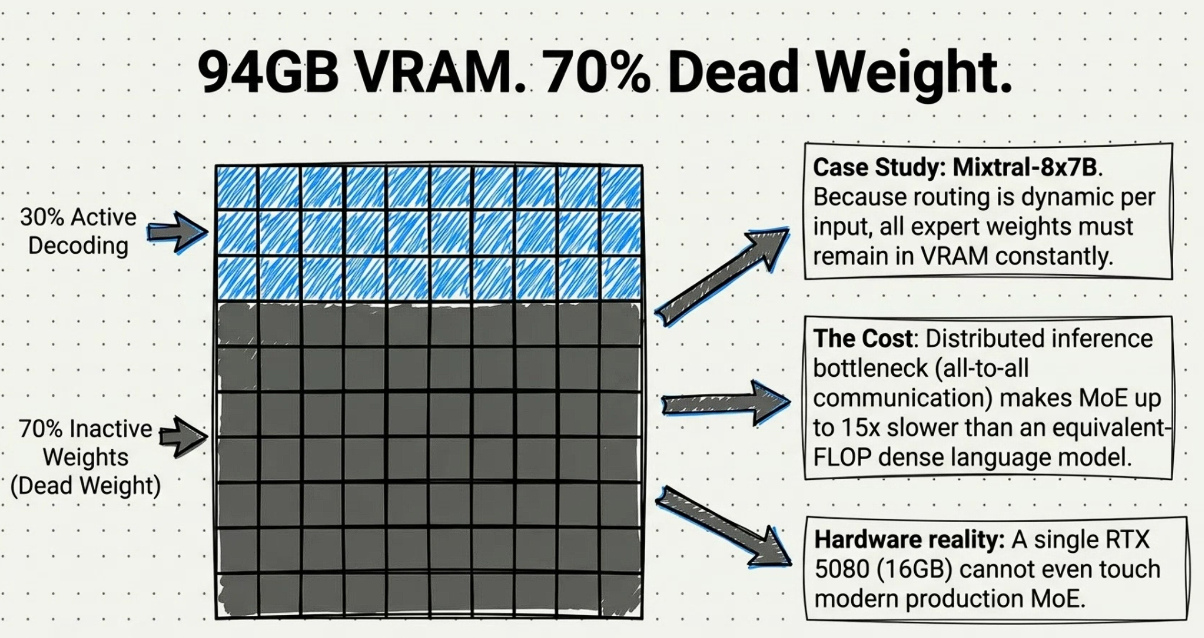
- H3 : ROuting dynamic - load toàn bộ - Lên quá trình inference thì ???
- Mình chưa dư đoán được cái routing động sẽ xài
- COst rất lớn gpu phải giao tiếp với nhau = làm cho moe - chậm hơn 15.
- Hardware bị đuối thì ?? thì cần kiến trúc nào - dđ
- Mình chưa dư đoán được cái routing động sẽ xài
Research Gap
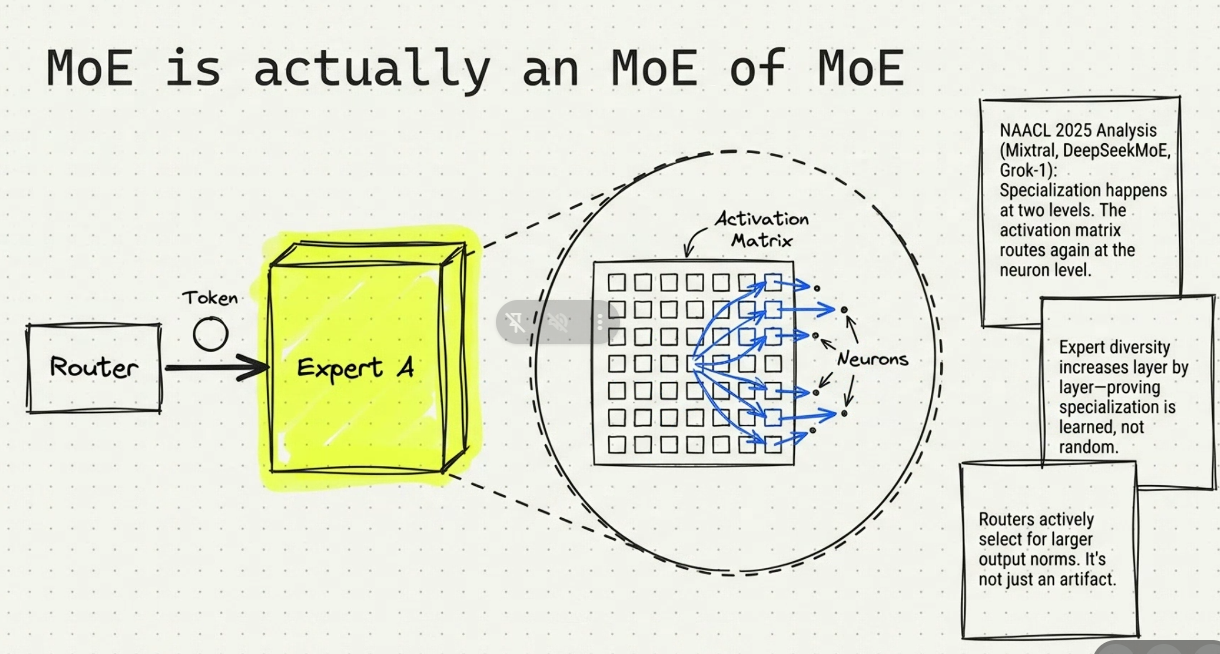
- HÌnh 1/1
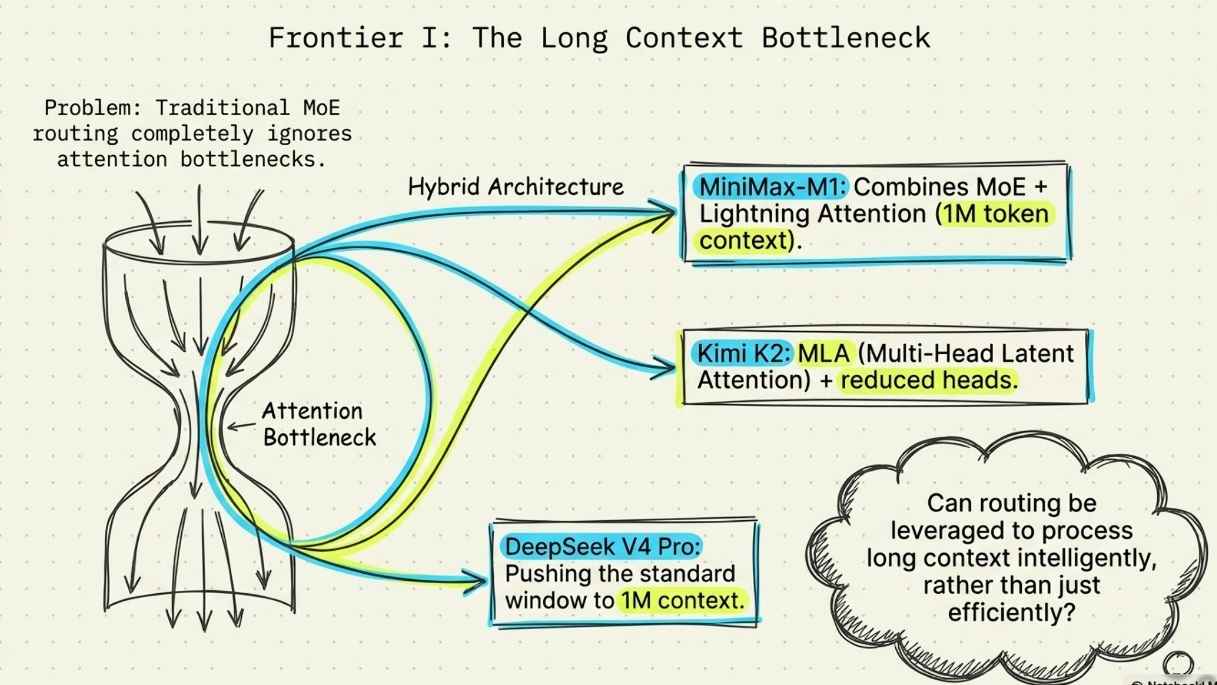
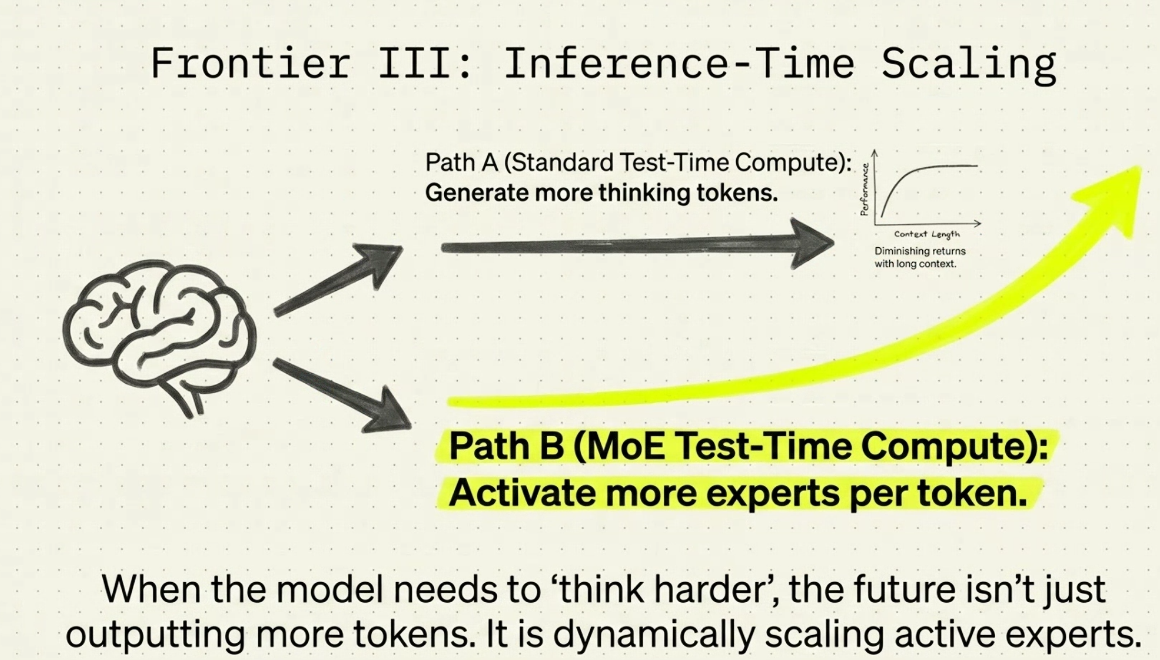
- H3: active token nhiều inference - thì cần nhiều hơn. Thêm chiều sâu sử lý hơn. nếu easy: 4 , complex: 6 - > adaptive refences.
- H4: Làm sao train rẻ hơn, -> Làm sao resoning tốt hơn -> làm sao routing tốt hơn? (HỌc hơn - hard code để thay vì fix cứng)
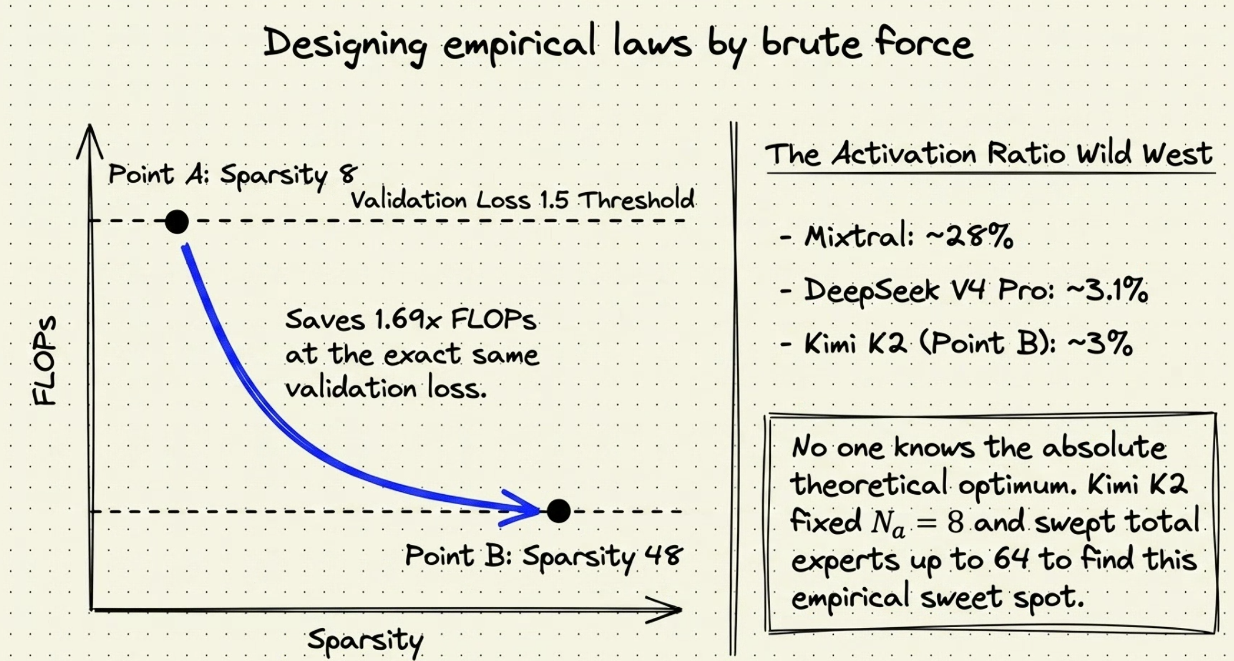
Kimi K2
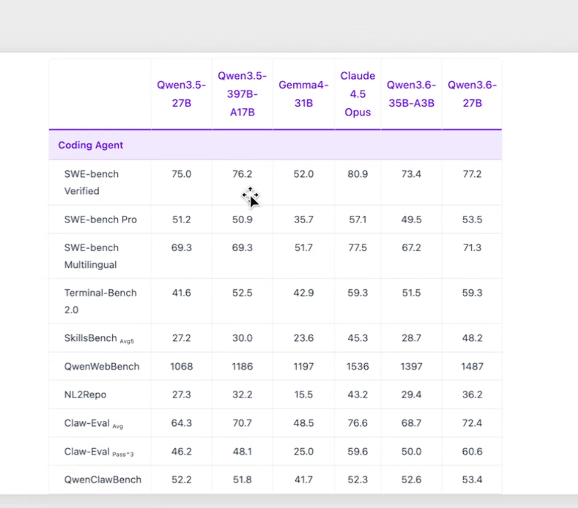
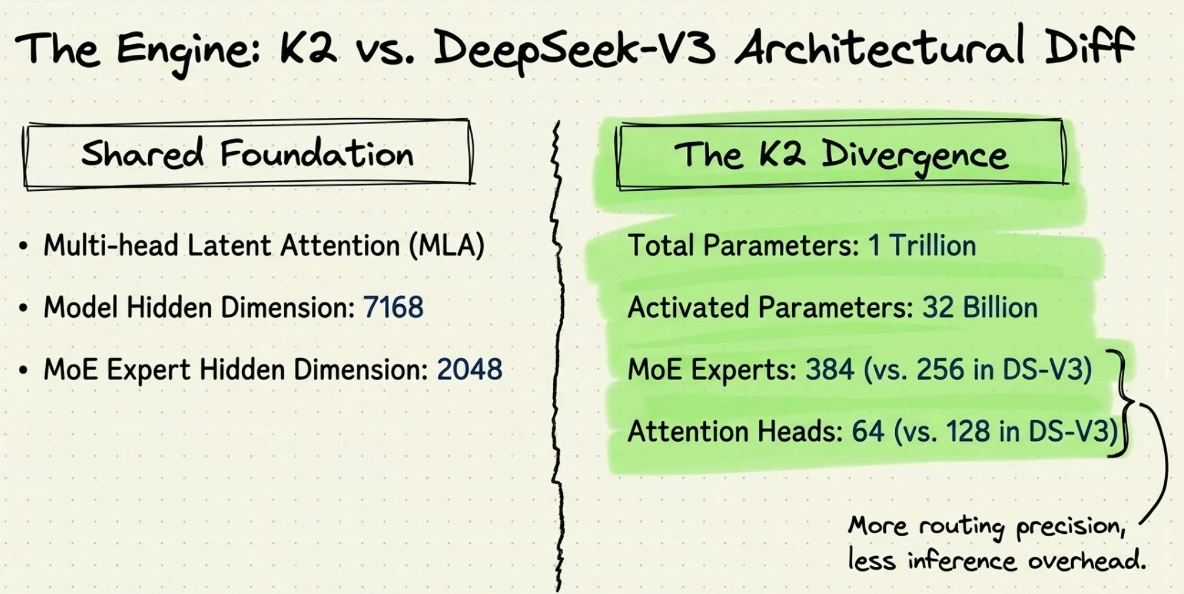

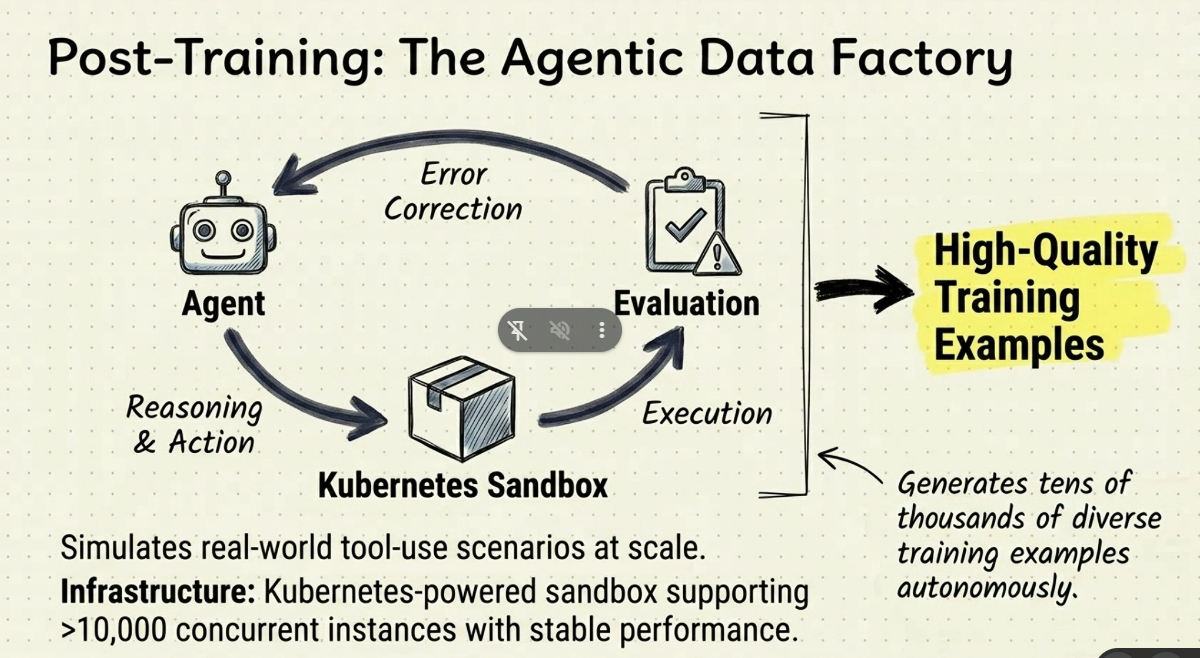

- H2: CHọn production giảm 128 -> 64 thì giảm: - rule ngay từ đầu
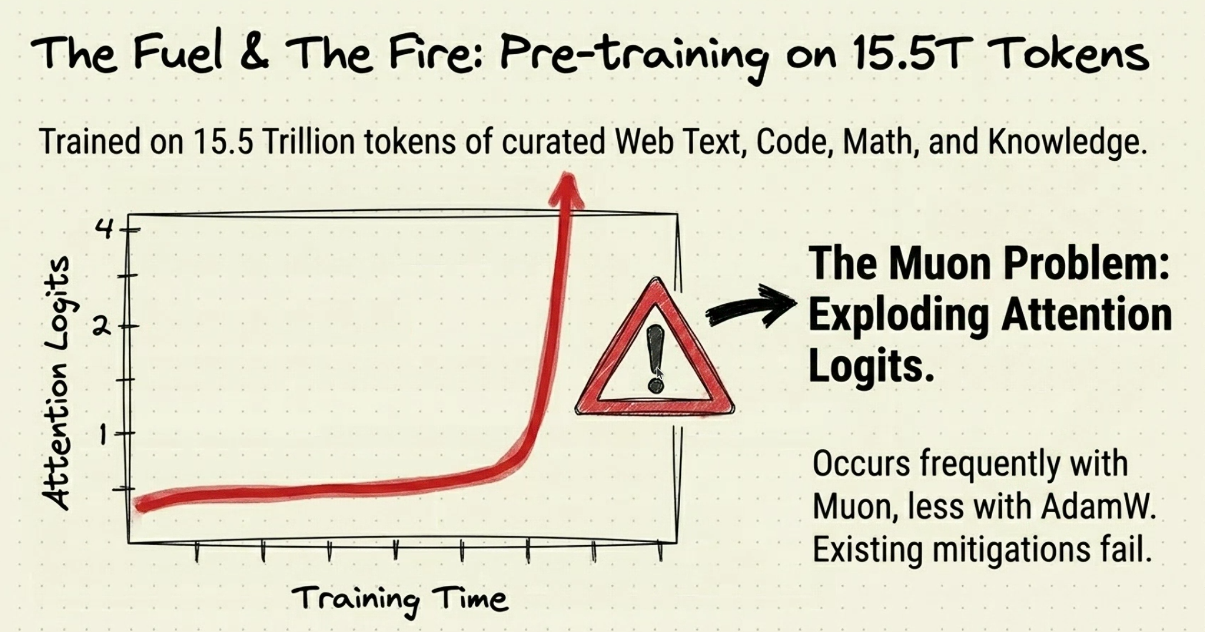
- H3: Muon problem - adam w, adam. đúng tối ưu con ma trận
- Muon - Q, K, V, ma trận của gating - muon
- Attention logit - nó bị bắn lớn, loss???-
- Moun CLip - QK Clip - rescales , Finetune không ổn định trên data lớn.
- Muon - Q, K, V, ma trận của gating - muon
- H4: Agent RL - > thu thập data để làm train chất lượng cao dự vào lỗi
- tạo train data 10k data - Loop.
- H5: Gian lận phần thưởng - Token budget-Control - Gắn max - Suy nghĩ hiệu quả trong thời gian giới hạn. - Scalling law moe ?. Rule force = load balance, specialization expert.
- Vẫn đang trong quá trình tạo ra expert.