Tiến độ
Công việc
Link:
Tiến độ
Tuần 1 - 7.4
- Tìm hiểu Large Reasoning Model: Khái niệm, yêu cầu và hướng phát triển.
- Tìm hiểu thêm về Agent: Nghiên cứu MoE, MLoops.
- Tìm hiểu cách viết đề cương: Xây dựng lộ trình phát triển, xác định phạm vi và kế hoạch thực hiện
Khó khăn: - Mơ hồ về hướng đi nên đang tìm hiểu các hướng có thể
Tuần 2 - 13.4
- Tiếp theo có thể làm hoàn thiện thêm data finetune để-> enhance embedding
- Model Confidence
- Tìm hiểu về GraphRAG, Explain retrieval trên Github
- Các phương pháp Explainable AI - NLP mà đã thực hiện rồi. (Có 1 buổi meeting youtube mình phải coi đã).
- TÌm hiểu và đang xây dựng bộ data để embedding model - để tăng khả năng tìm kiếm thông tin
- Tìm hiểu Graph Rag(Knowledge graph) - có demo về kiến thức của nó
- Tìm hiểu cơ bản về XAI: các kiến thức nền của nó từ XgBoost, RForest,
Khó khăn: Có nhiều kiến thức và kĩ thuật trong lĩnh vực này và chưa tìm hiểu hết và nắm rõ được
Tuần 3 - 20.4
- Tiếp tục tìm hiểu về XAI: LIME, SHAP,Feature Importance,.. trước đây
- Xây dựng tiếp bộ data embedding : Được tầm 60%
- Tìm đọc paper và các survey liên quan
Tuần 4 - 27.4
- Tìm hiểu thêm các bài về XAI gần đây: cách diễn đạt hay cách visualize để tăng độ tin cậy
- Tìm hiểu các bài paper liên quan lĩnh vực XAI và RAG
- Đang bắt tay xây dựng Graph Rag: đang bị lỗi
- Đang tìm hiểu các nền tảng Để sử dụng làm Knowledge graph.
Tuần 5
- Làm về Graph knowldege. Ra được thực nghiệm trong vòng 3 tuần tới.
- Làm được khung liên qua đến paper.
Tuần 6 4.5
- Xử lý data và test với các chunking - clean lại data các trường đại học.
- Phân tích số lượng từ nghĩ trong data để hiểu và xây dựng.
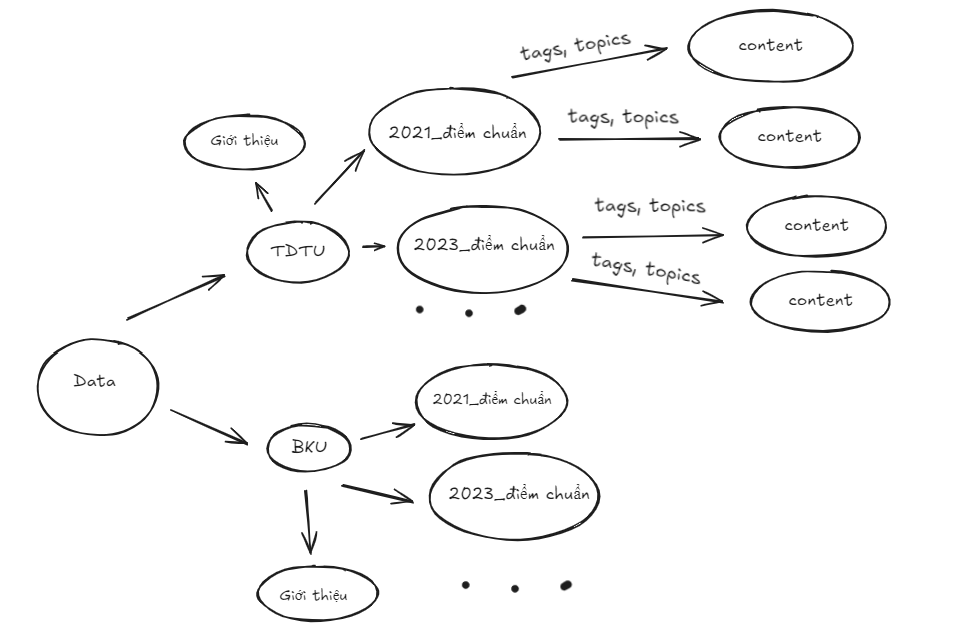
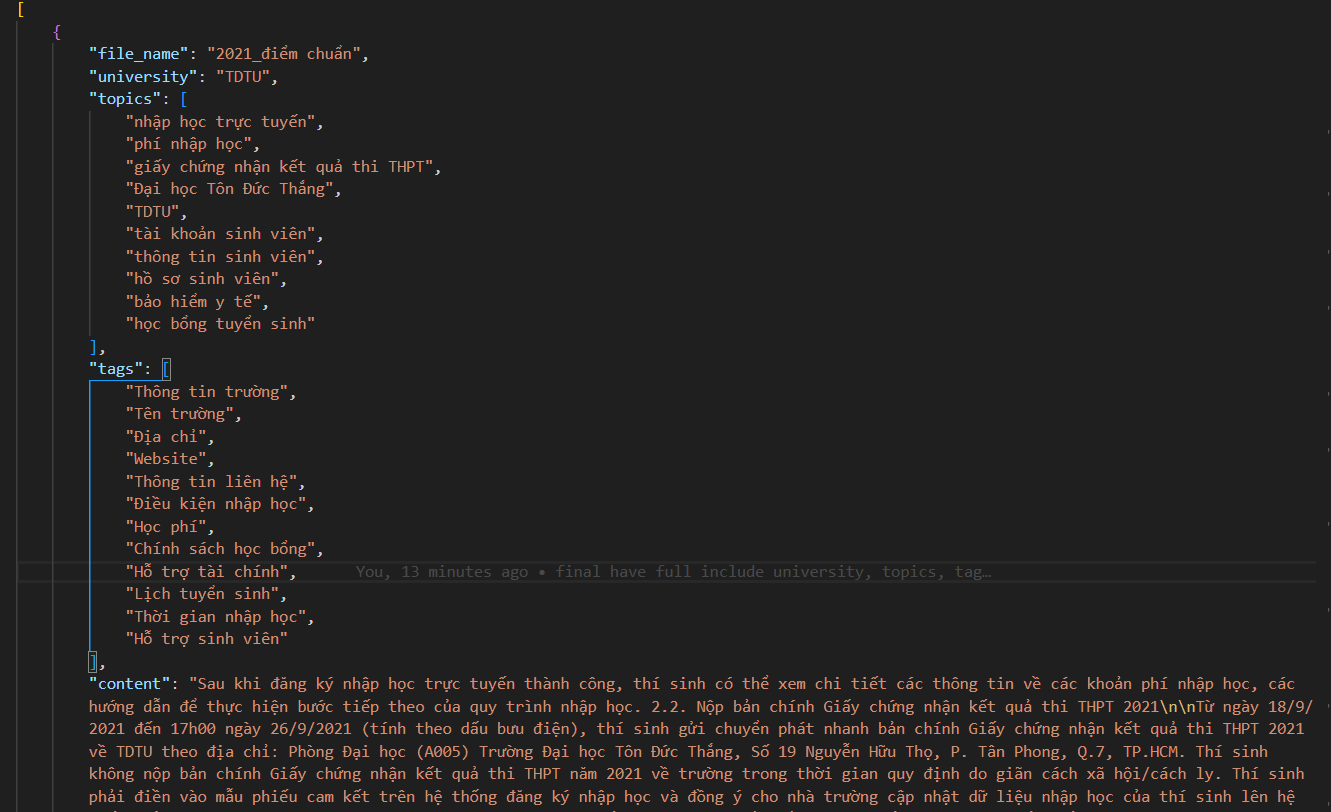
- Xây đựng bộ data graph: gồm filename, tags, topics. (60%)
Tuần 7 11.5
Note
- Đã gần như hoàn thành bộ graph (Lỗi 1 trường đại học)
- Trong quá trình làm nhận thấy 1 số lỗi trong quá trình xây.
- Đang thực hiện code để thực hiện hóa về graphrag bao gồm: KnowledgeGraph, QueryEngine, Visualizer.
- Quá trình xây gặp vấn đề về số lượng tags, topic nhiều quá nên k hiện thị đúng nội dung mong muốn
- Và sau khi tìm hiểu thêm là cũng dính vấn đề chunking dài quá đã làm không khái quát đủ tốt về graph
- Mình đang thấy cái hạn chế là cái embedding quá dài làm mấy đi khả năng xây graph knowledge.
- Có cảm giác không nên xây embedding quá dài mà phải clean lại data để cắt ngắn bớt.
- Data của HCMUTE đang bị lỗi nha. cần check lại sau.
Tuần tới
Đầu tiên là hướng đến là
- Phân cụm lại các tùy ý các content và
- Sau đó mới thử nghiệm là phải sort lại các file name để nó group lại khoảng cách.
Questions
- Thắc mắc về cách setup database.
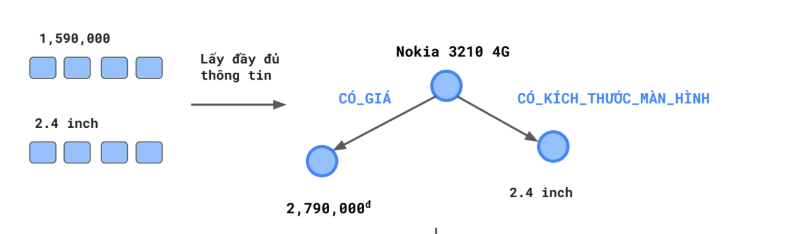
- nó là những câu nhỏ
- Nhưng về data của mình thì có ổn không? thầy có kinh nghiệm không ạ
Trong quá trình em tìm hiểu và tham khảo
- Các dạng chunking nó ngắn hơn và gọn hơn nhiều so với dạng data cũ của em.

Thầy cho em xin kinh nghiệm là em nên đánh topics và tags
- THì số lượng lấy tầm bao nhiêu nhiêu

Sai xót
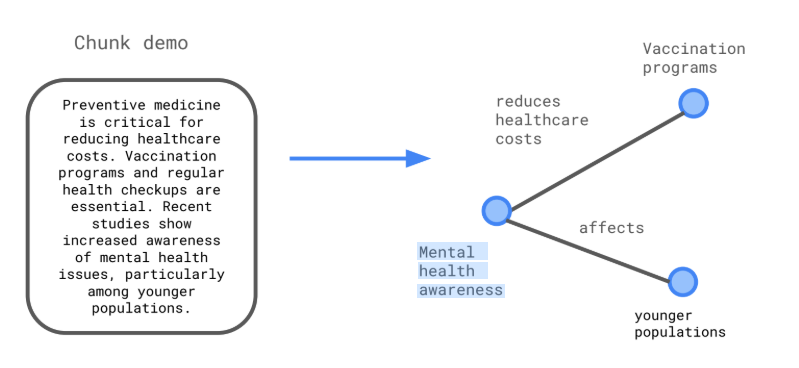
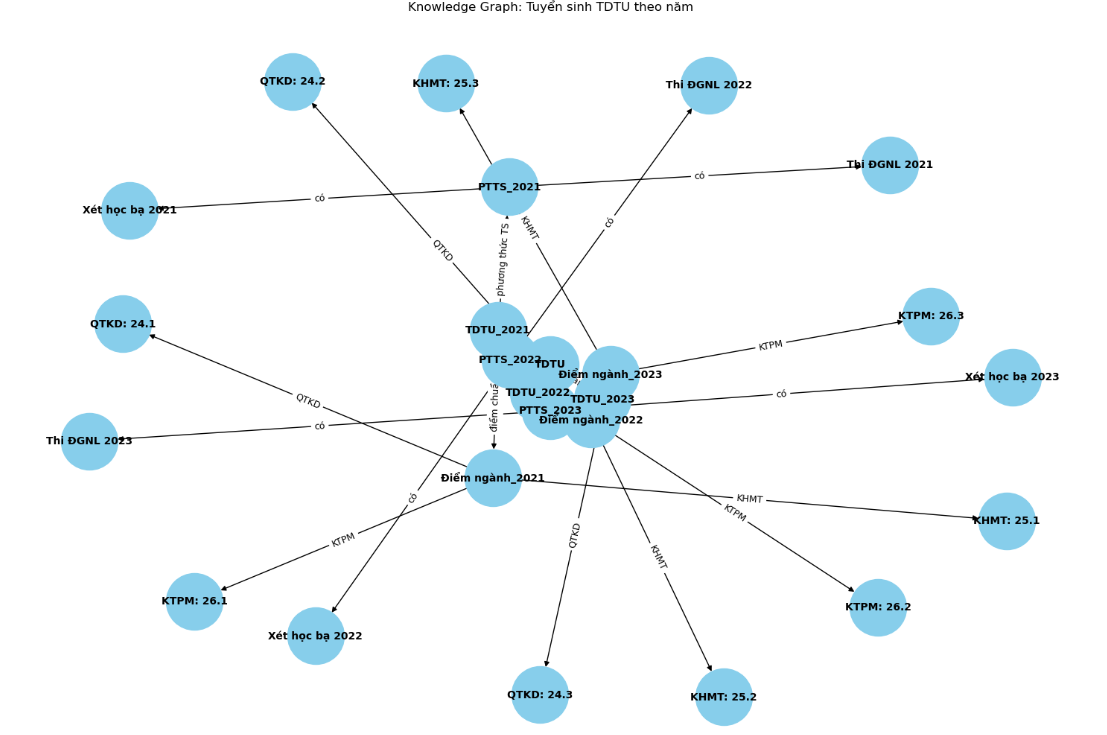
- Trong 1 chunk thì nó sẽ phải có 1 -3 topics thôi là tầm 3 chữ cái. Và mối quan hệ không quá dài. Để thể hiện được hình ảnh:
-
Mình đã tận dụng các semantic chunk của dự án trước để làm nên khi làm ra mới ngộ nhận ra vấn đề gặp phải.
-

-
Đây là cách giải quyết:
-
-
-
Tuần 8.
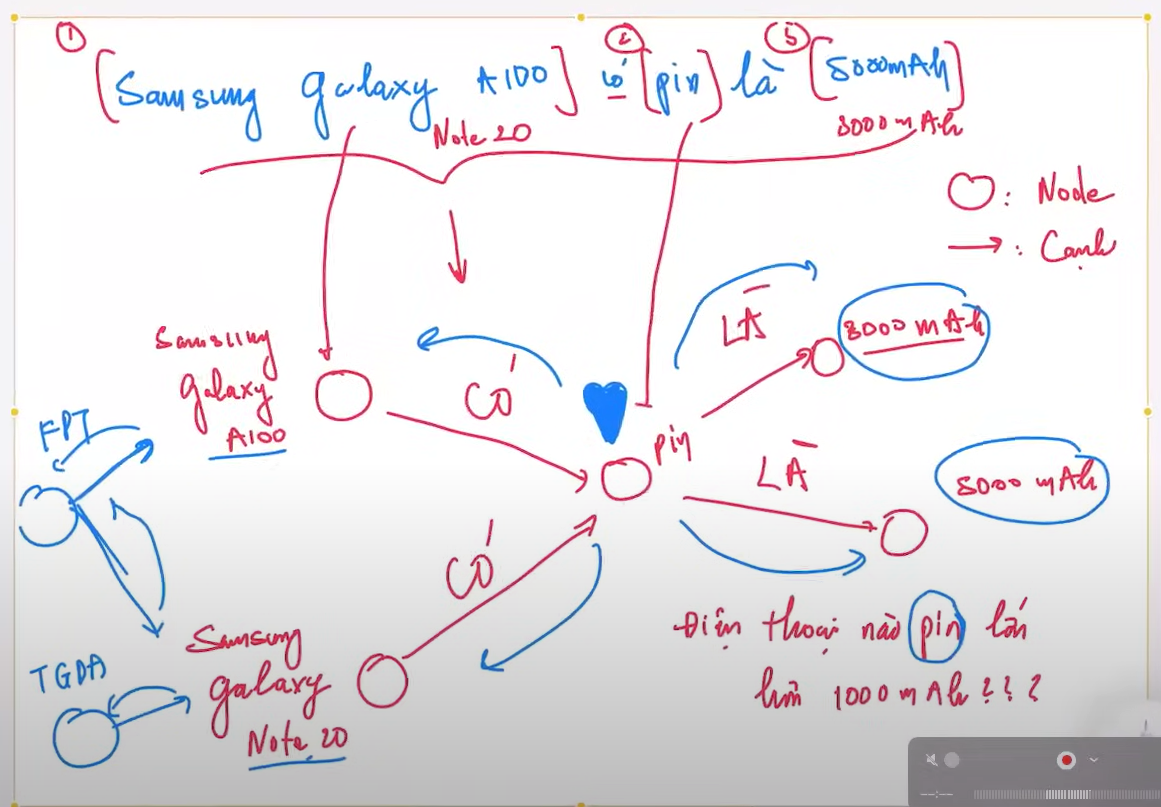
- Nếu là Concept thì nên lấy toàn bộ để làm ra đoạn đó lấy cả các thực thể và các key của nó luôn
- Ở đây code đang quy định là 3 đường ...
- Và nếu như lấy cách này thì nó sẽ hiện thị cái đầu tiên đại diện cho tên của node đi hay là embedding đi.
- THì nếu vậy thì khi semantic chunking chứ như bình thường nó không đại diện được và nó sẽ quá dài không tối ưu.
- Cái này nếu đúng sẽ cần chunking lại và ngắn hơn rất là nhiều.

Tạo ra thử project của 1 gmail và resquest thử xem nó như thế nào. 2 cái nó có trung 1 bill không
Tuần 8 18.5
- Tạo và hoành thành data chunking theo llm để tối ưu hơn
- Tách ra các topic của các trường theo lmm
- Tiếp tục fix bug và tối ưu lại code hệ thống của dự án cũ (query transformation, router).
- Điều chỉnh lại các prompt cho tối ưu hơn
Tuần 9 25.5
- Viết Code và xây dựng graph rag và xử lỗi.
- Tìm hiểu và tối ưu code cho dự án, clean lại code nhưng vẫn đang còn hạn chế
- TÌm hiểu về MCP cho kết nối data ở dưới và docker
Tuần 10 1.6
Viết code về Graph rag bao gồm xử lý data chunk, Query engine, Visualize đường đi lại, tìm ra được.
Test và tìm lỗi trong code
Thực nghiệm với 1 trường BKU và test ra các kết quả
Xây dựng data để làm benchmark
TUần 9- 8/6
Lấy của duy để có gợi ý làm
| - điều chỉnh boost điểm rerank cho yếu tố thời gian (mới > cũ) - xây dựng benchmark cho 2 phần là retrieval và generation: + retrieval: Recall@k, MRR và Hit@k + generation: ROUGE-L, BERTScore, ChrF và Avg Similarity (so với eval chuẩn nhưng chưa có) và Avg LLM latency |
- gặp vấn đề với bộ QA chưa đủ chính xác (do dùng Gemini), khó khăn trong việc tạo nên bộ benchmark chuẩn khi không có bộ evaluation đủ tốt - tìm hiểu và thấy được tập dataset https://huggingface.co/datasets/thangvip/vilawqa-syllo đầy đủ thông tin, đang trong quá trình tìm hiểu và tái sử dụng 1 số lượng nhỏ dữ liệu (dataset có 1000 dòng với 5 columns: question, syllogysim_answer, domain, refs, reference_texts) |
- tìm hiểu tạo tập evaluation để tạo cặp QA cho các câu hỏi pháp luật - tiếp tục điều chỉnh prompt tối ưu - thiết lập prompt cho model Gemini để tạo các cặp QA bao gồm nguồn cho câu trả lời với input là các văn bản pháp luật gốc đã được làm sạch |
Tạo ra thêm data để test đủ hơn nhiều khía cạnh trong knowledge.
Cần làm data embedding để lấy đánh giá.
THì neoj4 tách thử thể và benchmark thế nào. Cần chỉ số gì để so sánh.
Cần là benchmark cho dữ liệu.
Thực nghiệm với nhiều Embedding model
- Crawl data
- VIêt báo cáo.
Cần đi sâu 1 vô một model đi sâu vào data của model mình lấy tầm 3B gì đó để có
- 1 Case đúng
- Và bộ test case sai để ra kết quả như thế nào.
NEoj4 -> ....
- Dạng thực thể thì
Còn generate bằng model 2.5 - Tầm Tầm 2 Tiếng. Để generate.
Tuần 10 15/8
- Xử dụng 2 embedding model:
Dữ liệu
Nhận xét:
ragas_results_20flash_gemi_emb2
| Metric | Average | Count <0.5 | Count ≥0.5 |
|---|---|---|---|
| faithfulness | 0.9450 | 8 | 280 |
| answer_relevancy | 0.3763 | 125 | 163 |
| context_recall | 0.4647 | 139 | 149 |
| context_precision | 0.5069 | 142 | 146 |
| semantic_similarity | 0.8115 | 0 | 288 |
| answer_correctness | 0.3805 | 211 | 77 |
Hạn chế:
- Hạn chế là Lưu trữ embedding của các điểm node -node và lưu trữ của cả embedding. Cần ram lưu trữ để load là tới 7gb (trên colab - mang lên colab).
- Hiện tại thì em mới test vs dữ liệu câu đơn giản chỉ có 1 trường.
- Tách ra
Thầy nói l
- Nên viết dạng paper
- Cái thứ 2 thử finetune trên dữ liệu và test thử - Cái thứ 3 là test model deepseek và gwen.
12/7/2025
| Trường | Chunk cũ | Chunk mới | Tăng/Giảm | % thay đổi |
|---|---|---|---|---|
| VLU | 79 | 271 | +192 | +243% |
| TDTU | 78 | 399 | +321 | +411% |
| NTTU | 77 | 180 | +103 | +134% |
| HCMUE | 74 | 354 | +280 | +378% |
| OU | 65 | 231 | +166 | +255% |
| HCMUTE | 59 | 188 | +129 | +219% |
| UMP | 50 | 206 | +156 | +312% |
| UEH | 47 | 242 | +195 | +415% |
| UIT | 47 | 221 | +174 | +370% |
| BKU | 43 | 216 | +173 | +402% |
| UFM | 28 | 189 | +161 | +575% |
| HCMUS | 27 | 149 | +122 | +452% |
| FTU2 | 24 | 107 | +83 | +346% |
| FPT | 23 | 124 | +101 | +439% |
| PNTU | 16 | 75 | +59 | +369% |
| Tổng | 737 | 3,152 | +2,415 | +327% |
Saved combined data to: [E:\LLM_clone\KLTN\notebook\analyzeData\SemanticChunks\All_university.xlsx](file:///E:/LLM_clone/KLTN/notebook/analyzeData/SemanticChunks/All_university.xlsx)
KỊCH BẢN HỘI THOẠI CHATBOT TUYỂN SINH (PHÂN THEO 9 INTENT)
🔹 INTENT 1: Thông tin chung về trường
Mục tiêu: Giới thiệu cơ bản về tên trường, địa chỉ, sứ mệnh, website, liên hệ.
-
Nhận diện: "UIT là gì?", "Địa chỉ trường HCMUS ở đâu vậy?", "Trường nào thuộc ĐHQG?"
-
Follow-up: "Bạn đang quan tâm đến trường nào?"
-
Phản hồi:
-
"Trường Đại học Công nghệ Thông tin (UIT) trực thuộc ĐHQG TP.HCM, nằm tại Linh Trung, TP. Thủ Đức."
-
"Bạn có thể truy cập website chính thức tại https://uit.edu.vn hoặc liên hệ qua số 028.372 52002."
-
-
CTA: "Bạn có muốn biết thêm ngành đào tạo hoặc chỉ tiêu tuyển sinh không?"
-
Fallback: "Mình chưa rõ bạn đang hỏi về trường nào, bạn có thể nhập lại tên đầy đủ giúp mình không?"
🔹 INTENT 2: Ngành đào tạo và chương trình học
Mục tiêu: Giới thiệu ngành học, chuyên ngành, mô tả ngành, thời gian đào tạo.
-
Nhận diện: "UIT có ngành AI không?", "Học Công nghệ thực phẩm ở trường nào?"
- Follow-up: "Bạn muốn biết ngành này tại trường nào? (VD: UIT, BKU, TDTU...)"
-
Phản hồi:
-
"Ngành Trí tuệ nhân tạo tại UIT là chuyên ngành thuộc Công nghệ Thông tin, học trong 4 năm với nội dung gồm học máy, xử lý ngôn ngữ, thị giác máy tính..."
-
"Ngành Công nghệ thực phẩm được đào tạo tại TDTU, HCMUTE, và PNTU – mỗi trường có định hướng khác nhau (ứng dụng, nghiên cứu, thực hành)"
-
-
CTA: "Bạn muốn xem chi tiết chương trình học của ngành này không?"
-
Fallback: "Bạn vui lòng cung cấp thêm ngành học và trường cụ thể nhé!"
🔹 INTENT 3: Chỉ tiêu tuyển sinh
Mục tiêu: Thông tin số lượng chỉ tiêu, ngành, hình thức tuyển sinh.
-
Nhận diện: "Ngành An toàn thông tin có bao nhiêu chỉ tiêu?", "Trường có xét học bạ không?"
-
Follow-up: "Bạn hỏi ngành nào và trường nào nhé?"
-
Phản hồi:
-
"Ngành An toàn thông tin tại BKU có khoảng 300 chỉ tiêu."
-
"Trường có xét tuyển học bạ, điểm thi THPT và điểm Đánh giá năng lực tuỳ từng ngành."
-
-
CTA: "Bạn muốn mình gửi bạn link xét tuyển của trường không?"
-
Fallback: "Thông tin bạn cung cấp chưa đủ, bạn bổ sung tên ngành và trường nhé."
🔹 INTENT 4: Điều kiện nhập học và học phí
Mục tiêu: Cung cấp điều kiện đầu vào, giấy tờ, mức học phí, học bổng.
-
Nhận diện: "Điều kiện vào ngành Y là gì?", "Học phí ngành CNTT là bao nhiêu?"
-
Follow-up: "Bạn học chương trình đại trà hay chất lượng cao? Ở trường nào nhé?"
-
Phản hồi:
-
"Ngành Y đa khoa tại UMP yêu cầu điểm chuẩn cao, hồ sơ cần CMND, học bạ, giấy xác nhận ưu tiên..."
-
"Học phí ngành CNTT tại UIT khoảng 12-15 triệu/năm (đại trà). Chất lượng cao từ 30 triệu/năm."
-
-
CTA: "Bạn muốn xem thêm các loại học bổng hiện hành không?"
-
Fallback: "Chưa rõ ngành/trường nên chưa báo chính xác, bạn cho mình biết rõ hơn nhé."
🔹 INTENT 5: Lịch trình tuyển sinh
Mục tiêu: Cung cấp các mốc thời gian nhận hồ sơ, thi, nhập học...
-
Nhận diện: "Khi nào nộp hồ sơ vậy?", "Bao giờ có kết quả?"
-
Follow-up: "Bạn xét tuyển theo phương thức nào và tại trường nào nhé?"
-
Phản hồi:
-
"Xét tuyển học bạ tại TDTU bắt đầu từ 10/6 đến 15/7. Kết quả dự kiến công bố 22/7."
-
"Nếu bạn thi ĐGNL thì mốc tuyển sinh có thể khác, mình có thể gửi bạn link chi tiết."
-
-
CTA: "Bạn muốn chatbot nhắc lịch cho bạn qua email hoặc Zalo không?"
-
Fallback: "Bạn vui lòng cho biết thêm phương thức xét tuyển hoặc tên trường cụ thể."
🔹 INTENT 6: Chính sách hỗ trợ sinh viên
Mục tiêu: Giới thiệu các chính sách vay vốn, học tập, việc làm sau tốt nghiệp.
-
Nhận diện: "Có chính sách vay vốn không?", "Ra trường dễ xin việc không?"
-
Follow-up: "Bạn muốn biết về chính sách tại trường nào và ngành nào?"
-
Phản hồi:
-
"TDTU có chính sách vay vốn học tập qua ngân hàng chính sách."
-
"Sinh viên ngành CNTT tại UIT có tỷ lệ có việc sau 6 tháng ra trường lên đến 95%."
-
-
CTA: "Bạn có muốn biết thêm về các chương trình liên kết doanh nghiệp?"
-
Fallback: "Chưa rõ ngành hoặc trường, bạn cung cấp thêm nhé."
🔹 INTENT 7: Cơ sở vật chất
Mục tiêu: Cung cấp thông tin về thư viện, KTX, phòng lab, cơ sở đào tạo.
-
Nhận diện: "Trường có KTX không?", "Phòng lab có hiện đại không?"
-
Follow-up: "Bạn đang hỏi trường nào vậy?"
-
Phản hồi:
-
"UIT có 2 khu KTX lớn và phòng máy được trang bị GPU phục vụ AI."
-
"HCMUS có thư viện hiện đại mở cửa 7h–21h, rất phù hợp cho sinh viên nghiên cứu."
-
-
CTA: "Bạn muốn mình gửi bạn bản đồ cơ sở vật chất không?"
-
Fallback: "Mình chưa rõ bạn hỏi trường nào, có thể nhập lại không?"
🔹 INTENT 8: Chương trình đào tạo đặc biệt
Mục tiêu: Liên kết quốc tế, thạc sĩ, học song bằng.
-
Nhận diện: "Trường có chương trình du học không?", "Có học thạc sĩ CNTT không?"
-
Follow-up: "Bạn muốn học chương trình nào – liên kết, du học hay học sau đại học?"
-
Phản hồi:
-
"OU có liên kết với các trường tại Canada và Nhật – có chương trình 2+2."
-
"UIT có chương trình đào tạo thạc sĩ CNTT hệ chuẩn và hệ định hướng ứng dụng."
-
-
CTA: "Bạn muốn xem điều kiện tham gia chương trình không?"
-
Fallback: "Bạn chưa nói rõ loại chương trình bạn quan tâm."
🔹 INTENT 9: So sánh trường theo mục tiêu cá nhân
Mục tiêu: Hướng người học chọn đúng trường/ngành phù hợp định hướng cá nhân.
-
Nhận diện: "Nên học AI ở đâu tốt giữa BKU, UIT và HCMUS?"
-
Follow-up: "Bạn ưu tiên điều gì: chương trình học, cơ hội việc làm hay nghiên cứu?"
-
Phản hồi:
-
"UIT mạnh về AI thực hành, có nhiều lab hỗ trợ.
BKU có thương hiệu và hợp tác doanh nghiệp tốt.
HCMUS thiên về nghiên cứu, học thuật." -
"Nếu bạn muốn học CNTT nhưng cần thời gian tự học thêm kỹ năng khác, FPT và UIT là lựa chọn tốt hơn BKU."
-
-
CTA: "Bạn muốn xem bảng so sánh chi tiết không?"
-
Fallback: "Bạn chưa cung cấp đủ thông tin mục tiêu nghề nghiệp – bạn bổ sung nhé."

23/5/2025
- Embedding model cần tạo ra hoặc finetune model để ra kết quả như thế nào.
- GIao diện code
- Có chỗ explain kết quả - hightlight lại điểm chính
- Luồng là khi generate xong thì đã lưu database. Thì có get về rồi mới qua model explain để hiển thị
- Rồi có hiện thị kết quả recall, hay đánh giá gì cũng chỗ này.
- Giải thích retrieval
- Còn test thì phải chủ yếu dùng embedding để test.
- Visualize được đường đi - Graph rag và (graph rag qdrant (chưa thử)
- Còn langgraph thì chia ra làm các điểm node để gắn log để chạy các điểm time của từng cái.
- Nhấn mạnh embedding model (cần gì đã train dữ liệu gì ) - tạo ra kết quả benchmark có và không để chứng mình khả năng retrieval. *** important
- Có chỗ explain kết quả - hightlight lại điểm chính
9/8
16/8
CÒn những gì
- VIết báo cáo
- embedding:
- TÌnh nốt embedding của câu hỏi khó complex: TÍnh ra câu ground truth đã - xong r - mới tính - Kết quả retrieval - kq - generate.
- Sửa code:
- NOde động - và có đường đi
- CHain of thoughj
- Viualize
- enhance test embedding -
- mAYTROLASTOPKI.
- vậy là chạy 30 epoch
HCMUE, FTU2, HCMUS, UIT , VLU
https://chatgpt.com/c/68a9c739-664c-8326-b1f3-b504911c1330?model=gpt-5-thinking