Data evaluation
Data ground truth
Link
Review
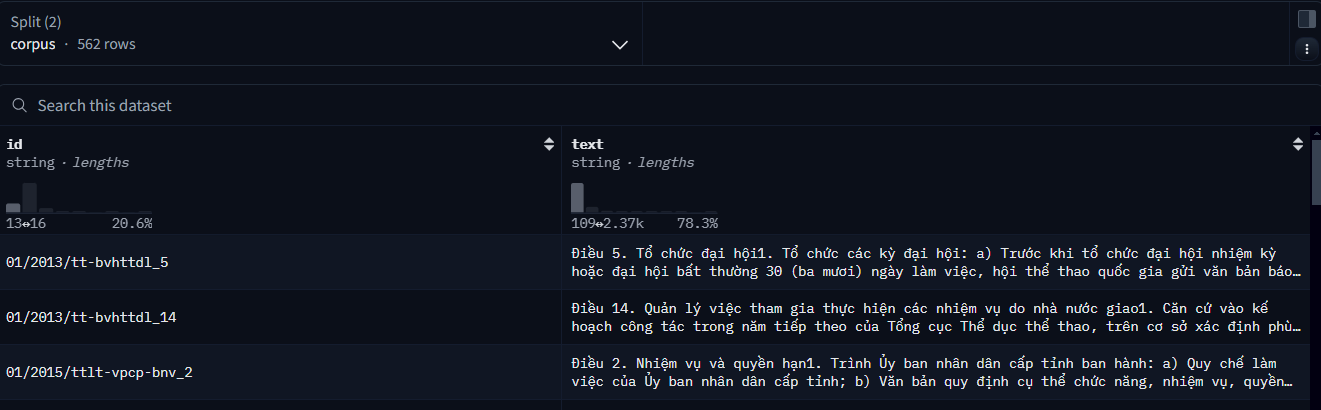
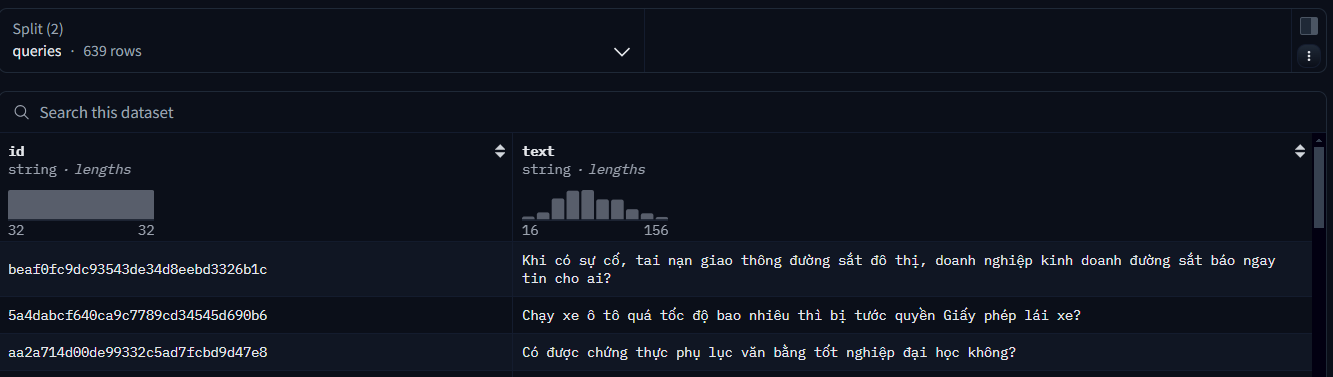
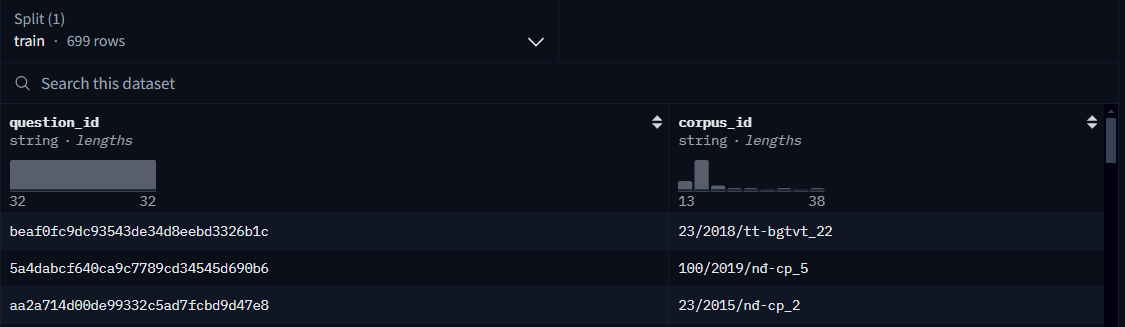
Ở đây là Anh hiếu dùng 2 repo data hugging face.
- repo1 dùng để lưu lại kết quả chunking (id_corpus, corpus text). Và ở đây còn tạo ra 1 data từ id question và câu hỏi.
- Repo2 lưu lại question id tương ứng với corpus_id: đây là bộ data test khả năng retrieval.
- có thể 1 question với 2 hoặc nhiều corpus id.
Note
- Trong bài blog của anh hiếu thì mục đích là nâng cao khả năng retrieval nên dùng bộ data này để fine tune model embedding để khả năng tìm kiếm vector của nó tốt hơn.
- Trên đó ảnh cũng đã có kết quả thì ảnh qua đoạn code thì ảnh cho thấy kết quả retrieval nó tốt hơn khi được finetune. Code enhance retrieval
- Nhưng trong bài tham khảo của Qdrant và của repo tên BeIR ảnh dùng bộ data kiểu anh hiếu để đánh giá khả năng retrieval. Họ dùng các metric để đánh giá : precission, recall, mrr, dcg, ndcg

Evaluation Metrics for Information Retrieval
1. Precision@K
Precision@K đo lường tỷ lệ số lượng kết quả đúng trong K kết quả đầu tiên.
Công thức:
Ví dụ:
Giả sử hệ thống trả về 5 tài liệu đầu tiên với độ liên quan như sau:
| Rank | Document ID | Relevant (1=Yes, 0=No) |
|---|---|---|
| 1 | D1 | 1 |
| 2 | D2 | 0 |
| 3 | D3 | 1 |
| 4 | D4 | 1 |
| 5 | D5 | 0 |
Tính Precision@5:
2. Recall@K
Recall@K đo lường tỷ lệ tài liệu liên quan được tìm thấy trong K kết quả đầu tiên so với tổng số tài liệu liên quan có trong tập dữ liệu.
Công thức:
Ví dụ:
Giả sử có tổng cộng 10 tài liệu liên quan trong toàn bộ tập dữ liệu, trong đó chỉ 3 tài liệu xuất hiện trong 5 kết quả đầu tiên:
3. Mean Reciprocal Rank (MRR)
MRR đo lường vị trí của kết quả liên quan đầu tiên trong danh sách kết quả.
Công thức:
Với (rank_i) là vị trí của kết quả liên quan đầu tiên cho truy vấn thứ (i).
N là tổng số truy vấn
Ví dụ:
Giả sử ba truy vấn có kết quả liên quan đầu tiên xuất hiện ở vị trí 1, 3 và 2:
4. Discounted Cumulative Gain (DCG@K)
DCG@K đánh giá chất lượng của danh sách kết quả bằng cách giảm trọng số của các kết quả có vị trí thấp hơn.
Công thức:
Với (rel_i) là mức độ liên quan của kết quả tại vị trí (i).
Ví dụ:
Giả sử danh sách kết quả có mức độ liên quan ([3, 2, 3, 0, 1]):
Bảng tính toán chi tiết:
| Rank | Relevance | $$(\log_2(rank+1))$$ | Contribution |
|---|---|---|---|
| 1 | 3 | 1.0 | 3.000 |
| 2 | 2 | 1.585 | 1.262 |
| 3 | 3 | 2.0 | 1.500 |
| 4 | 0 | 2.322 | 0.000 |
| 5 | 1 | 2.585 | 0.387 |
Tổng cộng:
5. Normalized DCG (NDCG@K)
NDCG@K chuẩn hóa DCG bằng cách chia cho giá trị DCG tối đa có thể đạt được (IDCG).
Công thức:
Với (IDCG@K) là giá trị DCG nếu kết quả được sắp xếp theo mức độ liên quan giảm dần.
Ví dụ:
Giả sử danh sách kết quả tối ưu có mức độ liên quan ([3, 3, 2, 1, 0]), ta tính IDCG@5:
Bảng tính toán:
| Rank | Relevance | $$(\log_2(rank+1))$$ | Contribution |
|---|---|---|---|
| 1 | 3 | 1.0 | 3.000 |
| 2 | 3 | 1.585 | 1.892 |
| 3 | 2 | 2.0 | 1.000 |
| 4 | 1 | 2.322 | 0.431 |
| 5 | 0 | 2.585 | 0.000 |
Tổng cộng:
Tính NDCG@5:
6. Mean Average Precision (MAP)
MAP là một chỉ số quan trọng, cung cấp một giá trị duy nhất tóm tắt chất lượng của danh sách xếp hạng.
Nó phản ánh toàn bộ precision-recall curve và nhạy với vị trí của tất cả các tài liệu liên quan trong danh sách kết quả.
Công thức
MAP được tính theo 2 bước:
- Tính Average Precision (AP) cho từng truy vấn.
- Lấy trung bình các giá trị AP đó trên toàn bộ tập truy vấn.
Average Precision (AP) cho một truy vấn:
Trong đó:
- (N): tổng số kết quả được trả về
- (R): tổng số tài liệu liên quan
- (rel(i)): hàm chỉ báo, bằng 1 nếu tài liệu ở vị trí (i) là liên quan, ngược lại bằng 0
Mean Average Precision (MAP):
Trong đó:
- (Q): tổng số truy vấn
- (AP_q): Average Precision cho truy vấn (q)
Ví dụ minh họa
Giả sử có 1 truy vấn, hệ thống trả về 5 tài liệu đầu tiên với độ liên quan:
| Rank | Document | Relevant (rel) | Precision@i |
|---|---|---|---|
| 1 | D1 | 1 | 1/1 = 1.0 |
| 2 | D2 | 0 | — |
| 3 | D3 | 1 | 2/3 ≈ 0.667 |
| 4 | D4 | 0 | — |
| 5 | D5 | 1 | 3/5 = 0.6 |
- Có tổng cộng R = 3 tài liệu liên quan (D1, D3, D5).
- Tính AP:
Nếu ta có nhiều truy vấn, MAP sẽ là trung bình của tất cả các AP đó.
Ý nghĩa
- MAP phản ánh độ chính xác trung bình trên toàn bộ danh sách xếp hạng.
- Nếu kết quả đúng xuất hiện sớm và đều trong danh sách, MAP sẽ cao.
- MAP được xem là thước đo chuẩn để so sánh các hệ thống tìm kiếm/thông tin.
Chuẩn rồi 👍 mình thêm luôn MAP (Mean Average Precision) vào danh sách để đủ bộ:
✅ Các chỉ số trong Information Retrieval (IR) → Càng cao càng tốt
-
Precision@K
-
Ý nghĩa: trong K kết quả trả về, bao nhiêu % là đúng.
-
Cao hơn = ít “rác” hơn trong top-K.
-
-
Recall@K
-
Ý nghĩa: trong toàn bộ tài liệu đúng, hệ thống tìm được bao nhiêu trong K kết quả.
-
Cao hơn = bao phủ nhiều kết quả đúng hơn.
-
-
MRR@K (Mean Reciprocal Rank)
-
Ý nghĩa: tài liệu đúng đầu tiên xuất hiện sớm đến mức nào.
-
Cao hơn = người dùng thấy câu trả lời đúng nhanh hơn.
-
-
DCG@K (Discounted Cumulative Gain)
-
Ý nghĩa: tài liệu đúng càng ở gần đầu danh sách càng được thưởng điểm.
-
Cao hơn = kết quả đúng được xếp ở vị trí ưu tiên.
-
-
NDCG@K (Normalized DCG)
-
Ý nghĩa: DCG được chuẩn hóa so với cách sắp xếp “lý tưởng”.
-
Cao hơn = thứ tự trả về gần giống với tối ưu.
-
-
MAP (Mean Average Precision)
-
Ý nghĩa: trung bình Precision tại tất cả các vị trí có kết quả đúng, sau đó lấy trung bình trên nhiều truy vấn.
-
Cao hơn = hệ thống ổn định chính xác trên toàn bộ danh sách kết quả, không chỉ vài vị trí đầu.
-
🔄 Mối quan hệ
-
Precision ↔ Recall: thường ngược nhau (chọn ít kết quả để chính xác hơn → Precision cao nhưng Recall giảm).
-
MRR: quan trọng khi người dùng chỉ xem kết quả đầu tiên (QA/Chatbot).
-
DCG/NDCG: quan trọng cho hệ thống tìm kiếm dài, vì đánh giá chất lượng toàn bộ xếp hạng.
-
MAP: tổng hợp cả Precision và Recall theo toàn bộ danh sách, được coi là thước đo chuẩn nhất để so sánh các hệ thống IR.
👉 Bạn có muốn mình làm một bảng tóm tắt gọn (Tên – Ý nghĩa – Khi cao nghĩa là gì – Ưu tiên cho use-case nào) để bạn chèn thẳng vào slide không?
Đánh giá RAG với Evaluate Ragas
1. Giới thiệu về Evaluate Ragas
Evaluate Ragas là một thư viện hỗ trợ đánh giá các hệ thống Retrieval-Augmented Generation (RAG). Nó cung cấp các tiêu chí đánh giá chất lượng của truy xuất thông tin và sinh văn bản, giúp tối ưu hóa mô hình RAG.
2. Các tiêu chí đánh giá
Ragas đánh giá hệ thống RAG dựa trên các tiêu chí chính:
- Context Precision: Đánh giá mức độ liên quan của ngữ cảnh được truy xuất.
- Faithfulness: Đánh giá mức độ chính xác của câu trả lời dựa trên ngữ cảnh.
- Answer Relevance: Đánh giá mức độ liên quan của câu trả lời với câu hỏi.
- Context Recall: Đánh giá mức độ đầy đủ của ngữ cảnh được truy xuất.
- Semantic Similarity: Đánh giá mức độ tương đồng ngữ nghĩa giữa câu trả lời và ground truth.
- Answer Correctness: Đánh giá tính đúng đắn tổng thể của câu trả lời so với ground truth.
3. Công thức tính điểm
3.1. Context Precision
👉 Tính tỷ lệ tài liệu truy xuất thực sự liên quan so với tổng số tài liệu truy xuất.
3.2. Faithfulness
👉 Kiểm tra câu trả lời có dựa trên bằng chứng trong ngữ cảnh không.
3.3. Answer Relevance
👉 Tính toán mức độ liên quan giữa câu trả lời và câu hỏi bằng cosine similarity.
3.4. Context Recall
👉 Đo lường mức độ đầy đủ của ngữ cảnh truy xuất.
3.5. Semantic Similarity
👉 Đánh giá mức độ gần nhau về mặt ngữ nghĩa giữa câu trả lời và ground truth, thường dùng embedding + cosine similarity.
3.6. Answer Correctness
👉 Kiểm tra câu trả lời có trùng khớp hoặc đúng về mặt nội dung với ground truth hay không (có thể dùng exact match hoặc fuzzy matching).
4. Dataset đầu vào
Dataset thường có 4 cột chính:
| question | answer | contexts | ground_truth |
|---|---|---|---|
| Câu hỏi của người dùng | Câu trả lời từ mô hình RAG | Ngữ cảnh được truy xuất | Câu trả lời đúng theo dữ liệu gốc |
question: Câu hỏi đầu vào cần trả lời.answer: Câu trả lời do mô hình sinh ra.contexts: Các đoạn văn bản được truy xuất để hỗ trợ trả lời.ground_truth: Câu trả lời đúng dựa trên dữ liệu có sẵn.
5. Cách tạo dataset
- Thu thập câu hỏi và câu trả lời gốc: Sử dụng dữ liệu từ nguồn đáng tin cậy.
- Thêm ngữ cảnh truy xuất: Tạo hoặc sử dụng mô hình RAG để lấy các đoạn văn bản phù hợp.
- Tạo ground truth: Gán câu trả lời đúng để so sánh.
- Lưu dưới dạng bảng dữ liệu: Sử dụng pandas để lưu dữ liệu dưới dạng CSV hoặc JSON.
Hay đấy 👍 — với RAGAS (Retrieval-Augmented Generation Assessment Suite), các chỉ số hơi khác so với IR truyền thống. Mình tóm gọn lại để bạn dễ đưa vào slide:
✅ Các chỉ số trong RAGAS (Càng cao càng tốt)
-
Context Precision
-
Ý nghĩa: trong những đoạn ngữ cảnh được hệ thống lấy về, có bao nhiêu % thực sự liên quan đến câu hỏi.
-
Cao hơn = ít “ngữ cảnh rác” → hệ thống trả lời tập trung hơn.
-
-
Context Recall
-
Ý nghĩa: trong tất cả ngữ cảnh liên quan, hệ thống đã lấy về được bao nhiêu.
-
Cao hơn = hệ thống thu hồi đầy đủ hơn, ít bỏ sót thông tin.
-
-
Faithfulness
-
Ý nghĩa: câu trả lời có bám sát, không bịa thêm ngoài ngữ cảnh hay không.
-
Cao hơn = câu trả lời trung thực hơn, giảm “hallucination”.
-
-
Answer Relevance
-
Ý nghĩa: câu trả lời có thực sự trả lời đúng trọng tâm câu hỏi không.
-
Cao hơn = câu trả lời sát nghĩa với intent của người dùng.
-
-
Semantic Similarity
-
Ý nghĩa: mức độ tương đồng ngữ nghĩa giữa câu trả lời của mô hình và ground truth (câu trả lời chuẩn).
-
Cao hơn = câu trả lời gần giống với câu chuẩn hơn, ngay cả khi diễn đạt khác.
-
-
Answer Correctness
-
Ý nghĩa: đánh giá tổng thể tính đúng đắn của câu trả lời (so sánh trực tiếp với ground truth).
-
Cao hơn = câu trả lời chính xác hơn về nội dung.
-
🔄 Mối quan hệ phản ánh
-
Context Precision vs Context Recall: giống IR → trade-off giữa “ít rác” và “đầy đủ”.
-
Faithfulness: rất quan trọng để tránh hallucination trong RAG.
-
Answer Relevance + Semantic Similarity + Answer Correctness: phản ánh chất lượng đầu ra, từ “liên quan” → “giống nghĩa” → “đúng thực sự”.
👉 Bạn có muốn mình làm một bảng so sánh gọn (Tên – Ý nghĩa – Khi cao nghĩa là gì – Ví dụ) giống như lúc mình làm cho IR, để đưa thẳng vào slide?